 Zhongye
Zhongye 

2025-06-13-从上下文工程到 Agent Harness Engineering


从上下文工程到 Agent Harness Engineering
范式转移:从编码者到 Agent 驾驭者
AI 时代的研发焦虑与反直觉现象
有一个很反直觉的现象:AI Coding 把代码的生成速度提高了整整一个数量级,可产品的交付速度却并没有跟着变快。 问题到底卡在哪里?答案是非编码的那部分工作量,正随着代码生成量的暴涨而指数级地膨胀。
把一次完整交付拆开看,真正写代码的环节大概只占三成时间,而这恰恰是 AI 用的最多的地方;紧接着的验证、QA 和测试要吃掉四成时间,至今仍高度依赖人工;部署、发布、灰度又占去两成,只能算部分自动化;剩下一成的排障、沟通和 Code Review,则几乎全靠人力。AI 把那块本就不算最耗时的环节压缩到了极致,却对占了七成的非编码流程无能为力。
这正是所谓的局部最优陷阱,人反而成了整条链路上最大的瓶颈——AI 写完代码之后,你得帮它 Review、帮它测试、帮它善后,工作量不降反升。
什么是 Harness Engineering?
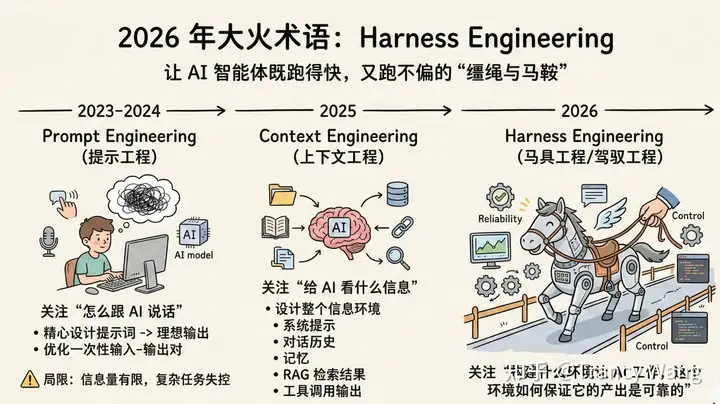
Harness 这个词的本意是”马具”:我们要完成的转变,是从一个使用模型的人,变成一个驾驭模型的人。「不要只把大模型看作’大脑’,必须为它打造专属的’工作室’。」
首先是任务形态的变化,从过去的代码补全走向 Agentic Coding——单次任务的运行时间从秒级一路拉长到分钟级乃至小时级。随之而来的是工程师角色的重新定位,工作重心从亲手”编写代码”转向”设计环境、明确意图、提供反馈”。而衡量这一切做得好不好的指标是 Agent 可读性:能不能把整个代码库重新塑造成一个模型能够”读懂”的环境。
整套方法论可以收敛到三个相互支撑的维度。 好的上下文精准布局 Prompt 结构、保护前缀稳定性,让 KV Cache 能够高效复用; 好的工具强调提供快速、结构化、带有”痛觉反馈”的 API,而不是一套面向人类操作的 GUI; 可读的环境则要求把一切从”对人友好”重新校准为”对 Agent 可读”的结构化语义,在下面进行阐述
Transformer 底层物理规律:Agent 的「硬约束」
Harness Engineering 的底层逻辑是处理模型的物理限制,强调模型对外界能力的应用
自回归生成:为什么是一个 token 一个 token 地吐?
绝大部分 LLM 的本质,是一个”下一个 token 预测器”。用形式化的方式写出来是这样:
P(x₁, x₂, ..., xₜ) = ∏ P(xₜ | x₁, ..., xₜ₋₁)
每生成第 t 个 token,都需要看完前面所有 t-1 个 token先把已有的前缀喂进模型,模型据此输出一个关于”下一个 token”的概率分布,然后从分布里采样或挑选出一个 token,把它拼回输入,如此循环往复,直到吐出终止符为止。
于是衍生出来一个问题:在没有 KV Cache 的情况下,要生成第 100 个词,模型得把前面 99 个词全部重新算一遍。上下文越长,这种重复计算就越离谱。也就是为什么塞进去一大坨 System Prompt 加代码之后,GPU 要”转很久”才肯出第一个字。
KV Cache:为什么「追加」便宜、「修改」昂贵?
要理解这一点,得先对 Self-Attention 里的 Q、K、V 有个直觉。 把 Query 理解成当前 token 想问的问题——“我指代的到底是前面哪个词?” 把 Key 理解成每个历史 token 的自我介绍或标签——“我是个名词/动词/时间状语” 把 Value 理解成每个历史 token 携带的详细语义内容,也就是具体的词义、情感和关系信息。 Attention 的计算,就是拿当前的 Q 和所有历史的 K 做点积打分,经过 softmax 得到注意力权重,再对所有 V 加权求和。
KV Cache 机制的聪明之处,在于把已经算过的 K 和 V 缓存下来。这样每来一个新 token,只需要计算它自己的 Q、K、V,再和缓存里的内容做一次 Attention 就行。
这就直接导致了一个极不对称的成本结构。追加(Append)极度便宜:老的 KV 全部可以复用,只需为新 token 算上这一次,增量成本是 O(新 token)。而修改中间内容则极其昂贵:一旦你改动了某个位置,它之后所有 token 的 KV 全部作废、必须重算,成本是 O(N)。
一切上下文工程,本质上都是为了「尽量不破坏前缀」 追加 = 复用 KV;修改 = 缓存作废
Prompt Cache:降本 90% 的工程杠杆
这套机制落到钱上,效果非常惊人。以 Claude Sonnet 的定价为例,基础输入大约是 $3.75/MTok(相当于 1.25 倍率),而一旦命中 Prompt Cache,Cache Read 的价格只要 $0.30/MTok,也就是 0.1 倍率——成本直接降低九成,同时推理速度大幅提升。
由此能引出几条很实在的工程启示。它更快,因为缓存了 KV 就能跳过 Prefill,首 Token 延迟大幅缩短;它更省,因为 Cache Read 只要基础价的十分之一;但它有个前提——前缀必须保持稳定,千万不要在开头塞时间戳、随机种子这类每次都在变的内容,否则缓存命中无从谈起。
Attention 数学推导与 Prefill/Decode 两阶段
把 Self-Attention 的完整公式写出来,前面的直觉就有了精确的落点:
Attention(Q, K, V) = softmax(QK^T / √d_k) · V
其中:- Q = X · W_Q (Query 矩阵,当前位置的"提问")- K = X · W_K (Key 矩阵,每个位置的"标签")- V = X · W_V (Value 矩阵,每个位置的"内容")- d_k = Key 的维度,用于缩放防止点积过大导致梯度消失- softmax 沿 K 的序列维度归一化,得到注意力权重 α实际模型里用的是 Multi-Head Attention,做法是把 Q、K、V 切成 h 个头,每个头各自独立做一遍 Attention,最后拼接起来:
MultiHead(Q, K, V) = Concat(head_1, ..., head_h) · W_O
head_i = Attention(Q · W_Q^i, K · W_K^i, V · W_V^i)
# 好处:不同的 head 关注不同类型的依赖关系# 有的 head 关注语法结构,有的关注语义相似性,有的关注位置关系推理过程其实分成性格迥异的两个阶段。Prefill(预填充)阶段的输入是整个 Prompt,可能多达数万 token,它要一次性把所有 token 的 K/V 都算出来并缓存,计算量很大但高度并行,决定的是首 Token 延迟(TTFT)。Decode(解码)阶段则每次只处理一个新 token,只算它自己的 Q/K/V 再和缓存做 Attention,单步计算量很小但天然串行,决定的是 token 之间的延迟(TBT)。
这正是工程上的要害所在: Coding Agent 塞进几万字上下文时,Prefill 阶段会变得极其昂贵——这就是”首 Token 延迟大”的物理根源,而 Prompt Cache 的全部意义,就是跳过 Prefill 里那段已经缓存好的前缀。
至于模型为什么只能”往前看”,靠的是因果 Mask:
Causal Mask(下三角矩阵):
t1 t2 t3 t4 t5t1 [ 1 0 0 0 0 ] ← t1 只能看自己t2 [ 1 1 0 0 0 ] ← t2 能看 t1, t2t3 [ 1 1 1 0 0 ] ← t3 能看 t1, t2, t3t4 [ 1 1 1 1 0 ]t5 [ 1 1 1 1 1 ] ← t5 能看所有前面的
# 0 的位置在 softmax 前被设为 -∞,确保未来信息不泄露# 这就是"自回归"的数学保证PyTorch 推理代码——看懂重复计算的代价
import torch
# model: 自回归语言模型 (input_ids) -> logits# tokenizer: 文本 <-> token id
# 1. 准备初始输入prompt = "给 user-service 加一个 /healthz 接口"input_ids = tokenizer.encode(prompt, return_tensors="pt") # shape: [1, prompt_len]
# 2. 自回归生成循环max_new_tokens = 200for step in range(max_new_tokens): # ⚠️ 关键问题:每一步都把"当前全部 token 序列"重新丢进模型 # 第 1 步:算 prompt (比如 20 个 token) # 第 2 步:算 prompt + 第1个新 token (21 个 token) # 第 50 步:算 prompt + 前49个新 token (69 个 token) # → 每轮都在重复计算前面 90% 一模一样的东西!
with torch.no_grad(): outputs = model(input_ids) # 重算整个序列的所有层
# 只关心最后一个位置的 logits next_token_logits = outputs.logits[:, -1, :]
# 选取概率最大的 token probs = torch.softmax(next_token_logits, dim=-1) next_token_id = torch.argmax(probs, dim=-1, keepdim=True)
# 把新 token 拼回输入,作为下一轮的输入 input_ids = torch.cat([input_ids, next_token_id], dim=-1)
if next_token_id.item() == tokenizer.eos_token_id: break
# 总计算量 ≈ O(prompt_len + 1) + O(prompt_len + 2) + ... + O(prompt_len + N)# = O(N * prompt_len + N²/2)# 当 prompt_len 很大(比如 10000 token)时,浪费极其严重带上 KV Cache 之后,思路就变成了”Prefill 一次性把 prompt 算完并缓存,之后 Decode 每步只喂一个新 token 并复用缓存”:
import torch
prompt = "给 user-service 加一个 /healthz 接口"input_ids = tokenizer.encode(prompt, return_tensors="pt")
# Prefill 阶段:一次性处理整个 prompt,缓存所有层的 K/Vwith torch.no_grad(): outputs = model(input_ids, use_cache=True) past_key_values = outputs.past_key_values # 缓存!每层的 (K, V) 张量
next_token_logits = outputs.logits[:, -1, :]next_token_id = torch.argmax(torch.softmax(next_token_logits, dim=-1), dim=-1, keepdim=True)
# Decode 阶段:每次只输入 1 个新 token + 复用缓存的 K/Vfor step in range(max_new_tokens - 1): with torch.no_grad(): outputs = model( next_token_id, # 只输入 1 个 token! past_key_values=past_key_values, # 复用之前所有的 K/V use_cache=True ) past_key_values = outputs.past_key_values # 更新缓存(追加新 token 的 K/V)
next_token_logits = outputs.logits[:, -1, :] next_token_id = torch.argmax(torch.softmax(next_token_logits, dim=-1), dim=-1, keepdim=True)
if next_token_id.item() == tokenizer.eos_token_id: break
# Decode 每步计算量 ≈ O(1 个 token 过所有层) + O(和缓存 K 做 Attention)# 相比朴素版,节省了重复计算 prompt 的巨大开销两相对比,结论一目了然:朴素版每步都重算全部,复杂度是 O(N·L); KV Cache 版的 Decode 每步只有 O(L)。当 prompt 达到一万 token 量级时,这中间的差距是万倍级别的。 这就解释了为什么所有推理服务都离不开 KV Cache,为什么”保护前缀稳定性”这件事如此要命——前缀一变,缓存就全废了。
三条约束,能带走的结论
所以三条物理约束各自对应着明确的工程含义和应对策略。自回归逐 token 生成意味着上下文越长、重复计算越多,所以要精简上下文、做治理而非堆砌;KV Cache 追加便宜而修改昂贵,意味着保护前缀稳定性就等于省钱加提速,因此永远是 append 而非 edit 前缀;上下文本身是最贵的资源,窗口有限且注意力会被稀释,应对之道是三段式布局、配合 Compaction 和把记忆外包出去。
上下文工程实战:Prompt 布局与膨胀对策
一次 Agent 任务背后 Prompt 的五层结构
敲下一句任务指令时,Agent 并不是把你这句话原封不动丢给模型,而是在背后悄悄构造了一整套相当精密的 Prompt 结构。它大致分五层,从稳定到易变排列下来是这样:
最底层是 System 层,包含模型服务商的系统提示、Agent 的身份定义和工具能力声明,稳定性极高,可以长期缓存; 往上是 AGENTS.md 层,写着技术栈、代码风格、安全边界和团队工作流,稳定性高,适合做项目级缓存; 再往上是项目快照层,记录当前工作目录、选中文本和项目结构,稳定性居中,做会话级缓存; 接着是会话历史层,囊括对话记录、工具调用与返回、各种 snapshot 和总结,它稳定性最低、还会持续膨胀,必须主动压缩; 最后是工具定义层,也就是 MCP 工具清单——名称、说明加 JSON Schema,稳定性高,可以长期缓存。
这里可以看出上下文绝不是”越多越好”,而是要”把最重要的东西放到最该放的位置”。位置和占比,直接决定了模型把注意力分配到哪里。
ReAct 循环
Coding Agent 和纯聊天机器人最大的区别,就在于它跑的是一套 ReAct(Reason + Act)循环。
这个循环从观察开始:当前的用户输入、历史对话加上工具输出,共同构成了 Agent 眼中的”世界状态”。
接着是思考,模型会在上下文里”自言自语”,分析现状、规划下一步该干什么。
然后进入行动,它调用 read_file()、write_file()、bash() 这类工具去真正影响物理世界。
行动产生的结果又会被追加回上下文,形成新的观察,从而触发下一轮循环。
麻烦也正出在这里:每一轮 ReAct 都会往上下文里追加”思路 + 工具调用 + 工具输出”这三样东西。Turn 1 时上下文还很短,到 Turn 5 就明显变长,跑到 Turn 20 基本已经爆炸。如果你的工具平均每轮要塞进超过 5000 token,那 Cache 命中率很可能早就崩了。
注意力分布的「U 型曲线」
Transformer 在长上下文下的注意力分布,会呈现出一条很有特点的 U 型曲线。头部相当于宪法,这里放着 System Prompt、AGENTS.md 和核心规则,权重最高,扮演着长期记忆的角色;中部则容易沦为噪音,历史对话、日志和那些被废弃的方案都堆在这儿,注意力被严重稀释,很快退化成背景噪声;尾部是真正的工作区,当前任务和关键代码都在这里,模型的决策也主要依赖这一段。
为什么会形成这样的 U 型?背后有三层原因叠加。一是训练带来的近因偏置,next-token 预测的目标让模型天生就偏爱”多看最近的东西”;二是位置偏置与信息汇聚效应,多层堆叠之后,开头的 token 会逐渐变成信息的汇聚点;三是序列位置效应,这有点像人背单词列表——开头和结尾总是记得最牢,夹在中间的最容易忘。
记忆的艺术:Compaction + AGENTS.md + Snapshot
应对上下文膨胀,第一招是主动 Compaction,也就是在关键节点把状态封装成文件。具体做法是让模型把当前这一长串对话浓缩成一个结构化的 snapshot 文件,写盘之后就把冗长的历史清掉:
# 让 Agent 总结当前状态并写入文件Agent "请把我们关于支付模块迁移的讨论,总结成 snapshot,写入 docs/state/payment-migration.md"
# 后续任务只需读取 snapshot 即可恢复上下文# 好处:有价值的中间状态可版本管理、可 review;对话不无限堆积第二招是写好 AGENTS.md,把它当成项目的”Prompt 宪法”。它应该承载那些稳定的长期规则:技术栈与框架选择、代码风格与错误处理约定、安全边界(哪些事坚决不能做)、团队工作流(比如测试优先、commit 规范)。反过来,那些一次性的需求、经常变动的信息、某次重构的临时目标、本周的活动安排,统统不该写进去——它们属于 Spec 或 Plan 文件。
把这些策略串起来看就四条:让前缀稳定,KV Cache 才好复用;用 Sub Agent、Snapshot、Spec 去替换冗长的历史,对话才不会无限堆积;把 AGENTS.md 里的写法钉死,所有 Agent 才会默认遵守同一部宪法;最后,把记忆外包给文件系统——任何没有落进代码仓库的隐形知识,对 Agent 而言就等于不存在。
工具设计哲学:给 Agent 打造「专属工作室」
工具,直接决定了模型的能力边界。工具不是给人用的 UI,而是给 Agent 用的 API。快、准、结构化,这三样缺一不可。
从「对人友好」到「对 Agent 可读」
过去的基础设施,给人准备了大量酷炫的 GUI 和海量的终端日志,可这些东西对模型其实并不友好——模型上下文有限,多模态能力也还不够强。范式转移的方向,是把这一切翻译成模型能用的形态。
面向鼠标点击的交互,要换成面向自然语言指令的接口;视觉冗余的图表,要换成高信噪比的诊断摘要,结构化输出;酷炫 GUI 和刷屏日志,要换成结构化语义的JSON 和 API,才能更好的和agent进行交互
好工具的三大标准
第一条标准是贴近物理上限、做到秒级响应。工具必须足够快,否则 Agent 会在等待中”走神”——冷启动加上响应都得在秒级完成,慢工具等于让 Agent 注意力涣散。
第二条标准是结构化输出,禁止 PDF 和截图。工具应当吐出 JSON 或 Markdown,而不是原始日志或图片。当上下文窗口紧张时,结构化的信息能用最少的 token 传达最多的语义。比如一个理想的报错应该长这样:
{ "ok": false, "error_type": "SyntaxError", "file": "src/components/Button.tsx", "line": 42, "column": 13, "message": "Unexpected token '}'", "suggestion": "Check for missing semicolon on line 41"}第三条标准是痛觉反馈,错误比正确更重要。错误信息其实是闭环的起点。基于 ReAct 循环,当模型调用工具撞上错误时,一份精确的错误反馈能让它离解决问题更近一步。最烂的返回是 {"ok": false, "error": "Something went wrong"} 这种——对人都没用,对模型更是毫无价值;而好的返回会把错误类型、具体信息和修复建议都讲清楚,例如 {"ok": false, "error_type": "PermissionDenied", "message": "No permission to write /etc/config", "suggestion": "Ask user to execute manually with sudo"},模型据此就知道下一步该怎么走。
Agent 内置工具的能力边界
Coding Agent 的”物理上限”,其实是被它内置的那几类工具硬生生框死的。**文件读写(File I/O)**负责列目录、读文件、写回和 patch 修改——少了它,Agent 既看不到也改不了代码,等于睁眼瞎,所以这类工具要支持 glob 搜索、增量 patch,还要在文件过大时给出提示。受控 Bash/Shell负责执行 npm test、lint、pytest 这类受限命令并返回 stdout/stderr——少了它,Agent 感知不到”真实运行结果”,只能凭逻辑空想,因此命令白名单、超时控制、输出截断加摘要都是必需的。网络搜索让 Agent 能查技术文档、API 文档、issue 和论坛——少了它,它对外部世界的认知就停留在训练数据的截止日,所以结果要结构化、要去重、要带上 URL 来源。**WebFetch(HTTP 抓取)**负责拉取 wiki 页面、接口文档和 issue 页面——少了它,Agent 看不到线上文档和真实接口定义,因此要能自动提取正文、去掉导航噪音并支持分页。不给它看 CI 日志的工具,它就只能猜 CI;不给它查监控的工具,它就只能猜服务到底挂在哪。工具决定了模型的物理上限,工具设计得好不好,直接决定了模型能不能摸到这个上限。
如果按能力层级把工具铺开,会形成一个从基础到高级的矩阵。 L1 是 File I/O 加 Bash,赋予读写代码和执行命令的能力,是所有 Coding Agent 的标配; L2 是 LSP、Lint、TypeCheck 这类感知层工具,让 Agent 能看到语法错误的”红线”,典型实现是把 apply_patch 和检查一体化; L3 是 Search 加 WebFetch,打通对外部知识和文档的访问,关键是带结构化摘要; L4 接入 CI/CD 的状态、日志和部署能力,让 Agent 感知构建和发布状态,往往通过 MCP 接入; L5 接入 Metrics、Logs、Traces,让它感知生产环境的健康度,对接 APM 或日志平台; L6 则是 Issue、MR、Notification 这类协作工具,让 Agent 真正参与到团队工作流里,通常借助 GitHub 或 GitLab 的 MCP 实现。
理想中的闭环校验工具应该把”编辑”和”检查”焊在一起,它的输入输出设计大致是这样:
# 理想的闭环校验工具设计def apply_patch_and_check(patch: str, files: list[str]) -> dict: """ 输入: - patch: unified diff 格式的代码补丁 - files: 受影响的文件路径列表
内部流程: 1. 应用 patch (git apply / 直接写入) 2. 跑一次 tsc --noEmit (TypeScript) 或等价 typecheck 3. 跑一次 eslint --format json (Lint) 4. 收集 diagnostics
输出格式: """ return { "ok": True | False, "patch_applied": True, "diagnostics": [ { "severity": "error", # error / warning / info "file": "src/api/health.ts", "line": 15, "column": 8, "code": "TS2322", "message": "Type 'string' is not assignable to type 'number'", "suggestion": "Check the return type of getHealthStatus()" } ], "summary": { "errors": 1, "warnings": 0, "files_checked": 3 } }
# Agent 拿到这个结果后:# - ok=True → 继续下一步(跑测试)# - ok=False → 根据 diagnostics 精确定位并修复,而非盲目重试健壮性:把分页和重试下沉到工具层
很多 API 天生带分页。如果你把翻页这件事原样丢给模型让它自己处理,几乎必出问题:上下文一长它就忘了参数,字段名写错、漏传 token 的概率极高,而且常常只看了第一页就急着”下结论”。凡是能在工具里做掉的健壮性,就别丢给模型去推理。模型擅长的是理解、归纳、规划和决策;它不擅长的恰恰是 next_page_token、边界条件和重试策略这些琐碎而确定的事。
LSP——Agent 的「红线感知器」
人写代码靠 IDE 的红色波浪线一眼看出错误。可对 Agent 来说,它只知道”我刚刚 write_file 了”,根本看不到语法飘红。
所以需要LSP能力来将编辑和检查做成一体:Agent 应用 patch 或编辑完文件后,自动触发 tsc --noEmit、lint 或 typecheck,把 diagnostics(文件、行、列、消息)结构化地收集回来;如果有错误,Agent 就根据这些诊断信息再改一轮,直到没有错误了,才考虑去跑测试。
收尾时就拿一份自检清单过一遍:这套工具的能力边界是否清楚(文件、bash、搜索、webfetch、LSP、CI 各自能干什么);它干得稳不稳,分页、重试、超时、默认参数是否都下沉到了工具层;它干完之后说没说清楚,有没有给出成功/失败/错误类型/位置/建议这样的结构化反馈;模型能不能看到结果,LSP、typecheck、lint 有没有把”红线”显式暴露出来;以及它知不知道什么时候该问人,遇到权限、风险、歧义类错误时能否引导走 AskUserQuestion。
多智能体架构:MCP / Skill / Sub Agent 的分工与协作
大脑分工:三种扩展机制
扩展 Agent 能力有三套机制,它们的定位截然不同。 MCP 工具的本质是”原子动作、常驻上下文”,一次性挂在上下文里提供基础能力,适合 GitHub、Slack、DB、K8s 这类 API 调用。Skill的本质是”可执行的 SOP、按需激活”,只有用到的时候才加载它的 skill.md、渐进式地注入上下文,适合 CI Debug、MR Review、重构流程这种有固定打法的场景。 Sub Agent的本质则是”独立的大脑、黑盒外包”,它完全隔离上下文,只和主 Agent 交换结构化摘要,适合并行探索、方案论证和长篇写作。
MCP——扩展模型的「手」
MCP 的核心,是把工具搬到了模型面前,扩展了它影响物理世界的能力边界。但这件事是有代价的:所有 MCP 工具的 Schema 都得常驻在上下文里、白白占着 token;工具数量一多,模型挑出正确工具的难度就直线上升;而且它只回答”我能做哪些原子动作”,并不回答”这些动作该怎么组合起来用”。
Skill——可执行文件夹 + SOP
Skill 不是一个缩小版的 MCP 工具,而是一整个可以执行的文件夹:
.Aiden/skills/ci-debug/ skill.md # 给模型看的 SOP / 使用说明(按需注入上下文) run.sh # 真正执行诊断的脚本 parse_log.py # 日志解析脚本 examples.md # 示例输入输出,帮助模型理解用法它的价值在于补上了 MCP 没回答的那个问题。Skill 会告诉模型”遇到这类问题,该按什么 SOP 去使用这些工具”;它按需激活,不在主 Agent 的上下文里常驻,用到时才加载,因此能省下上下文窗口;它把领域知识固化成了可执行的流程;而且它可以版本管理、可以审查,也能在团队之间复用。
Sub Agent——突破单 Agent 智能上限
单个 Agent 是有天花板的:上下文一膨胀,注意力就被稀释,智商也跟着被锁死。破局的办法,是把子任务交给独立的 Agent 去干。
最典型的应用是并行 Explore 模式。主 Agent 先识别出需要探索的三个微服务,然后 spawn 出三个并行的子 Agent,每个只读自己负责的目录、各自维护独立的上下文;子 Agent 在自己的沙盒里疯狂读文件、做内部推理、整理结构,最后各自产出一份结构化的 Summary;主 Agent 只需要读这三份 Summary,就能做出整体决策。
这背后的核心理念,是用”结构化通信”取代”无脑堆砌”——Agent 在彼此隔离的沙盒里工作,只交换摘要。这样既物理隔离了噪音,又能交叉验证,从而突破单 Agent 的智能上限。
实战编排
把三者串起来用,是一套很自然的编排:先用多个 Sub Agent 并行去做 Explore、分析和设计,把结果写进 docs、state 或 spec 文件;再回到主会话里,用 Skill 配合 MCP 工具,按 SOP 执行改动、debug 和检查;在关键的岔路口,则通过 AskUserQuestion 把人拉进来拍板。用架构隔离去对抗长任务的熵增——原子动作、固化打法、并行外包,层层递进。
人机协作与受控执行:Spec / Plan / AskUser
幻觉的根因:训练目标鼓励「有话就说」
大部分模型在训练时的奖励逻辑很简单:答对得 1 分,答错得 0 分,而”我不确定”这种回答极少被当成高分答案。从优化的角度看,这就埋下了祸根。在「不知道」和「猜一个看起来像样的答案」之间,模型从奖励角度更偏向后者。训练目标鼓励「有话就说」,而不是「搞不清楚就先问」—— 这就是幻觉的根源之一。
AskUserQuestion——把「先问人」变成一等公民
既然根子在系统层缺了一块,解法就是把”问人”本身做成一个工具,在系统层把它补上。
那么什么时候该放手让 Agent 自己跑,什么时候该第一轮就问人?判断的分界其实很清楚。当 Spec 足够明确、有闭环验证,工具能力覆盖完整,而且失败可以自动回退时,就放手让它跑;反过来,一旦意图模糊、存在多条可走的路径,或者环境信息不足、又或者牵涉到不可逆的操作,那就别犹豫,第一轮就该向人求助。
好的工具链让 Agent 清楚地知道自己能做什么、不能做什么——这本身就是一种 Harness。不确定就问人,是一个被鼓励的正确行为,而不是无能的表现。
Spec Kit——用结构化需求压缩「瞎猜空间」
直接丢给 Agent 一句”写一个贪吃蛇游戏”,它就得去猜平台、猜技术栈、猜控制方式、猜功能范围……熵高得离谱。正确的做法,是先通过几轮问答,把模糊的需求捏成一份结构化的 Spec:
# 项目基本信息name: "Snake Game"version: "1.0.0"author: "auto-generated via Agent + Human review"
# 技术选型(消除 Agent 猜测空间)project_type: "web"language: "TypeScript"framework: "React"rendering: "Canvas 2D"build_tool: "Vite"package_manager: "pnpm"
# 游戏配置grid: rows: 20 cols: 20 cell_size_px: 25
# 操控方式control_scheme: "WASD" # 备选: "arrow_keys" | "swipe" (mobile)touch_support: false
# 游戏机制speed: initial: "medium" # 初始速度 acceleration: true # 是否随分数加速 max_speed_multiplier: 2.5 # 最大加速倍率
# 功能清单(每一项都是明确的 Yes/No)features: - id: "score-board" description: "右上角实时显示当前分数和历史最高分" priority: "P0" - id: "pause" description: "按 Space 暂停/恢复,暂停时显示半透明遮罩" priority: "P0" - id: "auto-restart" description: "死亡后 3 秒自动重新开始,显示最终分数" priority: "P0" - id: "food-types" description: "普通食物 +1 分,金色食物 +5 分(10% 概率刷新)" priority: "P1" - id: "wall-mode" description: "碰墙死亡(非穿越模式)" priority: "P0"
# 验证标准(Agent 自动化测试的依据)success_criteria: - "蛇能正常移动,方向切换无延迟" - "吃到食物后蛇身增长 1 格" - "碰墙或咬到自己时游戏结束" - "分数正确累加并持久化到 localStorage" - "暂停/恢复功能正常" - "Canvas 在 60fps 下无明显卡顿"
# 不做的事情(明确边界,防止 Agent 过度发挥)out_of_scope: - "多人模式" - "关卡系统" - "皮肤商店" - "移动端适配" - "音效"
# 目录结构约定directory_structure: src/: "源代码" src/components/: "React 组件" src/game/: "游戏核心逻辑(纯函数,不依赖 React)" src/hooks/: "自定义 Hooks" src/types/: "TypeScript 类型定义" tests/: "Vitest 单元测试"有了这份 Spec,后续所有任务都指向它。每次构造 Prompt 时,Agent 都会把 Spec 读进来当作约束:
# 每次构造 Prompt 时,Agent 会读入 Spec 作为约束Agent "根据 specs/snake-game.yaml,实现核心渲染和键盘控制逻辑"
# Agent 在一个「已约束好的实现空间」里搜索,而不是凭空想象# 不确定的点(Spec 里没写的),会触发 AskUserQuestionSpec 和 AskUserQuestion 是天生一对:Spec 负责把不确定项显式地暴露出来,AskUserQuestion 负责在关键字段填不满时向你要真相,然后所有的实现、测试、文档生成都基于这份 Spec 展开。幻觉空间就这样被结构化约束硬生生压掉了一大块。
再往上抽象一层,Spec 和 Plan 各管一头。Spec(规格说明书)回答”做成什么样”——输入输出的 Schema、副作用的边界、验证通过的标准;Plan(执行计划)回答”怎么做”——多步任务的拆解、关键检查点、失败时的回退策略。一句话
Plan 模式实战:慢就是快
与其让 Agent 一头扎进迷雾里乱撞,不如分三步走。先进入 Plan 模式,让它把局面看清楚——“列出适合今天做的任务""写一份小 RFC”;再让人类审阅,在 RFC 或 Plan 这一层做修改和确认;最后切到 Execute 模式,确认无误后再让 Agent 照着 Plan 动手实现。这样做的好处,是在 Spec 和 RFC 层就把歧义消灭掉,让意图沉淀成一份可复用的文件,而不是飘在对话里随时可能走样。
端到端闭环交付:从 Review 代码到 Review 交付物
这里有一个关键转变:人的注意力是有限的,而 Agent 的注意力近乎无限。所以不要再去逐行 Review 代码,而要去 Review 交付产物——单测有没有覆盖关键 Case?上线之后稳不稳?
理想的 AI 自迭代闭环是这样运转的:以自然语言描述需求作为输入;Agent 理解需求后自动定位并修改代码;接着调用内置的测试 Skill,在沙盒里自动化自测验证;最后自动沉淀出交付文档——变更说明、前后对比、测试报告。人到最后只需要审阅三件事:到底改了什么、前后对比如何、又增加了哪些测试来确保稳定。
构建可复用工作流:从 .Aiden/ 到插件化
用 .Aiden/ 描述你的 Agent 系统
要把零散的能力沉淀成体系,可以在项目里约定一个配置目录,把所有 Agent、Skill、Command 编排进去:
.Aiden/ agents/ planner.yaml # 规划 Agent:写 Spec/RFC/Plan worker.yaml # 执行 Agent:按 Plan 实现代码 reviewer.yaml # 审查 Agent:检查质量与安全 skills/ ci-debug/ # CI 诊断 SOP generate-tests/ # 自动生成测试 refactor-module/ # 模块重构流程 commands/ migrate-payment.yaml # 支付迁移全流程 fix-issue.yaml # 根据 Issue ID 修 BugCommands——串联多 Agent 的流水线
一条 Command 就能编排出一整套完整的工作流:先调 Planner Agent 生成或更新 Plan,再 spawn 多个 Sub Agent 并行去 Explore 旧系统,接着用 Worker Agent 按 Plan 执行迁移,然后让 Reviewer Agent 做质量审查,关键步骤再通过 AskUserQuestion 把人拉进来确认。最终呈现给你的,就是一句话的事:
Aiden "migrate-payment 从旧网关迁到 v2 网关"# 背后执行的是你设计好的整套工作流,而不是「临时拍脑袋的 prompt」打包为团队级预设 / 插件
当你把 AGENTS 宪法、成熟的 Agent 配置、若干 Skill 和一批 Commands 都打磨成型之后,就可以把整个 .Aiden/ 打包成模板或插件,放到团队内部、甚至公开的”市场”里,让其他项目一键安装、直接复用整套工作流。这一步完成的转变意味深远——从”每个人自己写 prompt、自己踩坑”,走向”团队和社区沉淀出一套 Agent 系统,大家一键复用”。
AI Native 工具的代表:Midscene.js
传统的网页操作,是让 Agent 去模仿人类:获取 DOM 树、解析截图、定位元素、模拟点击。活还没真正开始干,光这一套下来上下文就已经消耗了三四万 token。
AI Native 的解法完全换了思路:让 Agent 直接用自然语言描述意图——“点击登录按钮""验证购物车里有 3 件商品”——工具原生地去理解并执行,自主定位、自动适配、自愈重试。两种方式的差距很直观:传统方式要获取几千行的 DOM 结构、靠截图识别吃掉大量 token、做易错的坐标计算、再脆弱地模拟点击;而 AI Native 方式既不获取 DOM,也不截图,更不模拟人类操作,自然语言本身就是操控接口。
好的 Harness,就是为 Agent 量身打造 Native 工具。Token 大幅下降,效果大幅提升。
总结
完整知识体系:从底层到应用
把全文的脉络从底层往上叠起来,正好是七层。最底下的 L1 模型物理层是 Transformer 自回归,逐 token 生成是物理铁律,对策是精简上下文、治理而非堆砌;L2 推理优化层是 KV Cache 与 Prompt Cache,追加便宜、修改昂贵,要靠保护前缀稳定性来降本九成;L3 上下文工程层讲 Prompt 布局与 Compaction,记住头部是宪法、尾部是工作区、中部是噪音,落地手段是 AGENTS.md 加 Snapshot 加文件系统外包;L4 工具设计层的核心是 Agent 可读性,工具要结构化、秒级、有痛觉反馈,配合 LSP 闭环、自动分页和错误建议;L5 协作架构层是 MCP、Skill、Sub Agent 的”原子→SOP→并行外包”三级跳,用隔离上下文来对抗熵增;L6 人机交互层是 Spec、Plan、AskUser,讲究谋定而后动、不确定就问,Spec 答 What、Plan 答 How;最顶上的 L7 工作流层则是把 .Aiden/ 配置化,让经验沉淀成可执行的工作流,通过 Commands、插件市场实现团队复用。
AI 时代研发的四个方向
如果只带走四句话,那应该是这四个方向。其一,从编码者到 Builder,这是角色的根本转变——Harness Engineering 的工作就是为 AI 提供工具、上下文和反馈,编写代码本身的价值在急速下降,而设计 Agent 工作环境的价值在急速上升。其二,驾驭模型的物理限制,模型说到底只是一个巨大的函数,当你摸清了 Transformer 自回归、KV Cache、Prompt Cache 这些边界,焦虑自然会大幅消退。其三,连接物理世界,模型能在多大程度上影响现实,取决于你给它什么状态、什么工具,精准的工具加上结构化的上下文,才能让模型真正落地。其四,时间是稀缺资源,人的时间永远是最稀缺的,把验证、测试、文档这些繁琐活儿交给 AI,才能把人的创造力释放到决策和设计上去。
AGENTS.md 模板
# AGENTS.md — 项目 Agent 宪法
## 项目概述
- **项目名称**: [你的项目名]- **技术栈**: TypeScript / React 18 / Node.js 20 / PostgreSQL- **包管理器**: pnpm (严禁使用 npm / yarn)- **构建工具**: Vite 5.x- **测试框架**: Vitest + React Testing Library- **代码风格**: ESLint (airbnb-typescript) + Prettier
## 代码规范
### 命名约定
- 组件: PascalCase (`UserProfile.tsx`)- 工具函数: camelCase (`formatDate.ts`)- 常量: SCREAMING_SNAKE_CASE- 类型/接口: PascalCase, 接口不加 I 前缀- 测试文件: `*.test.ts` / `*.spec.ts`
### 错误处理
- 所有 async 函数必须 try-catch,禁止 unhandled rejection- 错误必须结构化: `{ code, message, context }`- 面向用户的错误信息必须友好且可操作- 日志使用 `logger.error()` 不用 `console.error()`
### 文件组织
- 每个文件单一职责,不超过 300 行- 公共逻辑提取到 `src/utils/` 或 `src/shared/`- 业务逻辑与 UI 分离(hooks / services / components)
## 安全边界(禁止做的事情)
### 绝对禁止
- ❌ 删除 `migrations/` 目录下的任何文件- ❌ 修改 `.env.production` 或任何生产环境配置- ❌ 执行 `rm -rf`、`DROP TABLE`、`TRUNCATE` 等破坏性命令- ❌ 在代码中硬编码密钥、token、密码- ❌ 绕过 TypeScript 类型检查 (禁止 `@ts-ignore`,`as any` 需注释原因)
### 需要确认才能做
- ⚠️ 修改数据库 schema (migration)- ⚠️ 修改公共 API 的入参/出参- ⚠️ 升级主要依赖版本 (major version)- ⚠️ 修改 CI/CD 配置
## 工作流程
### 开发流程
1. 先写测试(或至少先写测试骨架)2. 实现功能3. 跑 `pnpm lint` + `pnpm typecheck` 确认无错误4. 跑 `pnpm test` 确认测试通过5. 写有意义的 commit message (Conventional Commits)
### Commit 规范
- `feat:` 新功能- `fix:` 修复 bug- `refactor:` 重构(不改变行为)- `test:` 测试相关- `docs:` 文档- `chore:` 构建/工具链
### 不确定时的行为
- 如果需求不明确 → AskUserQuestion,不要猜- 如果有多种实现方案 → 列出 2-3 个方案的 tradeoff,让人选- 如果涉及安全边界 → 必须确认,不要自行决定- 如果改动范围超过 5 个文件 → 先写 Plan 让人确认
## 常用命令
```bashpnpm dev # 启动开发服务器pnpm build # 构建生产版本pnpm test # 运行测试pnpm lint # Lint 检查pnpm typecheck # TypeScript 类型检查pnpm db:migrate # 运行数据库迁移```对于大型项目,AGENTS.md 还可以按角色分层管理。根目录的 AGENTS.md 是全局宪法,写技术栈、安全边界和通用规范;src/api/AGENTS.md 作用于后端 API 层,写路由规范、中间件约定和错误码标准;src/components/AGENTS.md 管前端组件层,写组件设计规范、Props 命名和状态管理;tests/AGENTS.md 则管测试层,写测试命名、mock 策略和覆盖率要求。这里有个关键原则
Skill 模板
一个完整的 Skill 目录长这样:
.Aiden/skills/ci-debug/│├── skill.md # [必须] Skill 说明文档 — 模型按需读取├── run.sh # [推荐] 主执行脚本├── parse_log.py # [可选] 辅助脚本├── examples.md # [推荐] 示例输入输出└── config.yaml # [可选] Skill 元配置其中最核心的 skill.md 可以参照下面的模板来写:
# CI Debug Skill
## 何时使用
当 CI/CD pipeline 失败时,使用本 Skill 诊断问题根因。
## 前置条件
- 需要 MR 编号或 Pipeline URL- 需要 `bash` 和 `webfetch` 工具可用
## 执行步骤
### Step 1: 获取 Pipeline 状态
```bash./run.sh status <pipeline_url>```
输出: JSON 格式的 job 列表及状态
### Step 2: 定位失败 Job
从 Step 1 输出中找到 status=failed 的 job
### Step 3: 拉取关键日志
```bash./run.sh logs <job_id> --tail 200```
输出: 最后 200 行日志
### Step 4: 分析错误
根据日志内容分析根因。常见模式:
- `ENOMEM` → 内存不足,检查资源限制- `exit code 137` → OOM Killed- `timeout` → 执行超时,检查是否有死循环- `permission denied` → 权限问题,检查 CI 变量
### Step 5: 给出修复建议
基于分析结果,给出具体的修复建议。如果不确定根因 → 调用 AskUserQuestion 问人。
## 注意事项
- 本 Skill 仅做诊断,不直接修改代码- 涉及 secret/token 的日志行自动脱敏- 如果 3 轮分析仍无法定位,请求人工介入后续行动
其实实践这一套方法论也不难: 在项目根目录建一份 AGENTS.md,写清技术栈、代码风格和安全边界;凡是重复了三次以上的流程,就为它建一个 Skill 文件夹(CI debug、MR review、重构 SOP 都是好候选); 给关键工具加上结构化的错误返回,至少包含 error_type、file、line 和 suggestion;在 Agent 工作流里接入 LSP 和 Lint 闭环,让编辑之后自动 typecheck; 用 Spec 和 Plan 模式取代”直接让 Agent 干活”,先 RFC 再实现;把 AskUserQuestion 的策略写进 AGENTS.md,明确”不确定就问人”; 对那些超过二十轮的长任务,用 Sub Agent 做上下文隔离;并且定期做主动 Compaction,把冗长的对话浓缩成 Snapshot 文件。
关于这一块也没有什么最佳实践和SOP,所以最后的最后,具体的场景还是要看具体的解决方案会好些
分享到社交平台
将本文分享给你的朋友们
评论
音乐
暂无播放