 Zhongye
Zhongye 

2026-07-25-[RFC]-Glushkov_OGAS
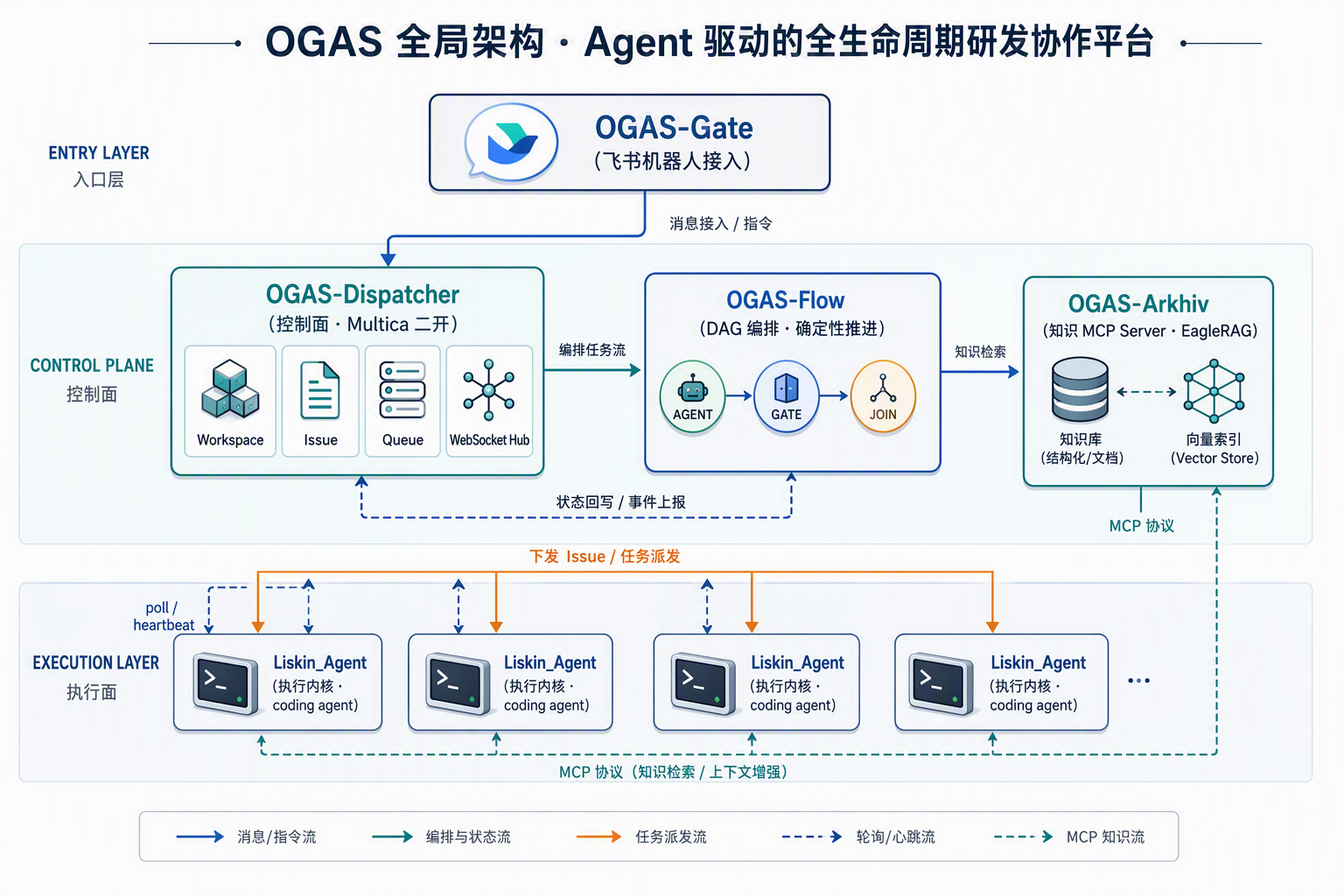
OGAS 是一个自托管的 Agent 研发生命周期协作平台。它让整个团队能以受控、可编排、可回滚的方式驱动 Agent,从一个需求的知识检索,一路自动推进到代码交付和线上部署。
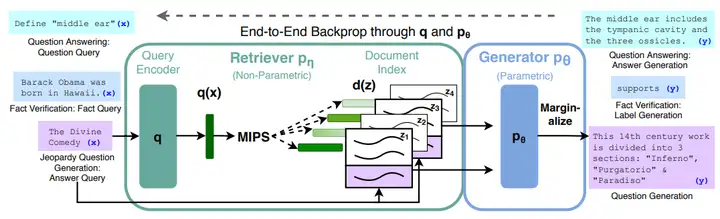
2026-07-15-Agentic RAG 系统实践:从知识检索到自主行动
记录一些将 RAG 检索能力封装为 MCP 服务的工程方案,构建一个能理解私域知识和调用外部工具的 Agentic RAG 系统,在生产环境中支撑多轮复杂问答与自动化任务,实现从“被动回答”到“自主行动”的跨越。
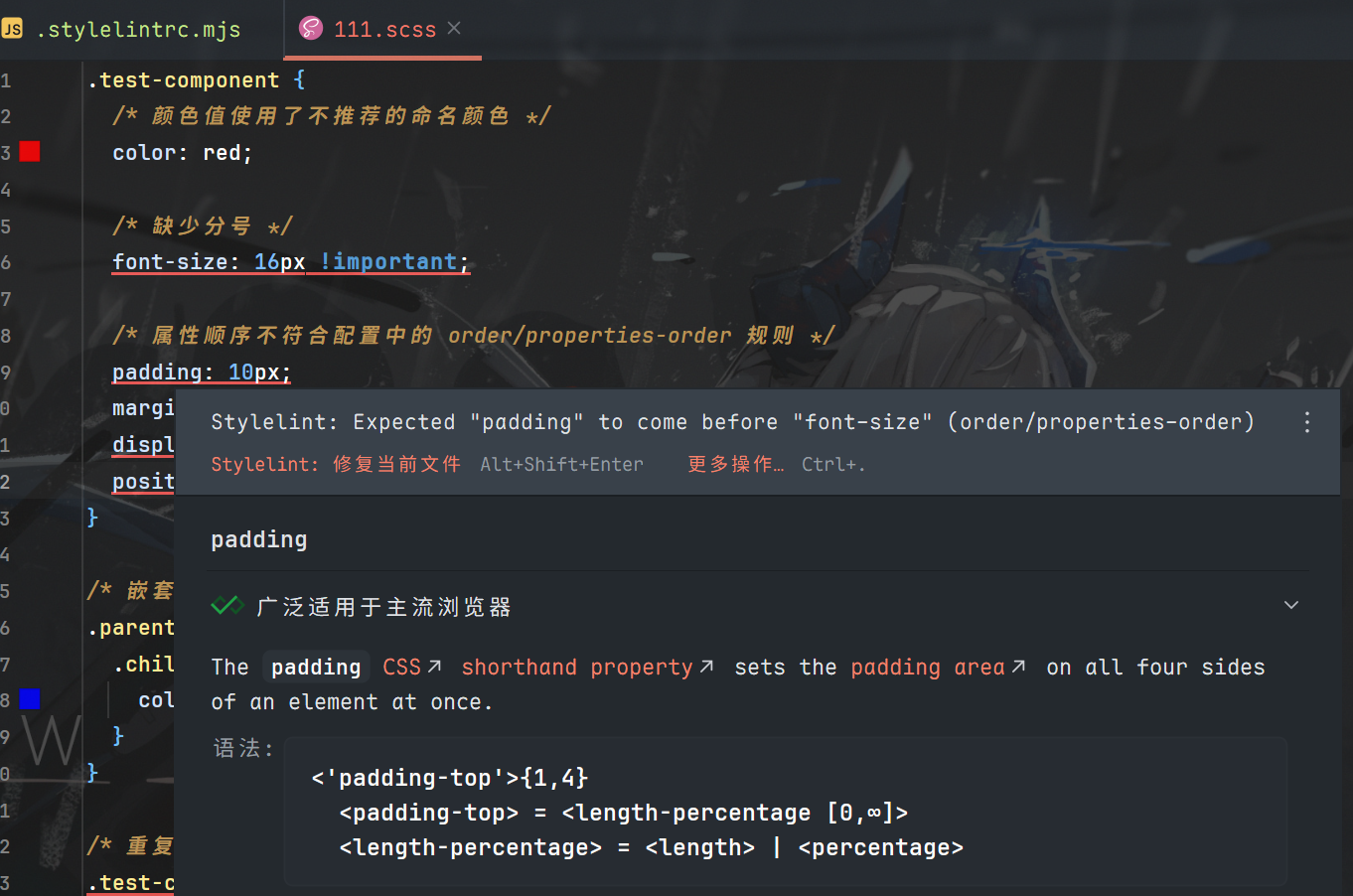
2026-07-13-简谈前端基建标准与落地
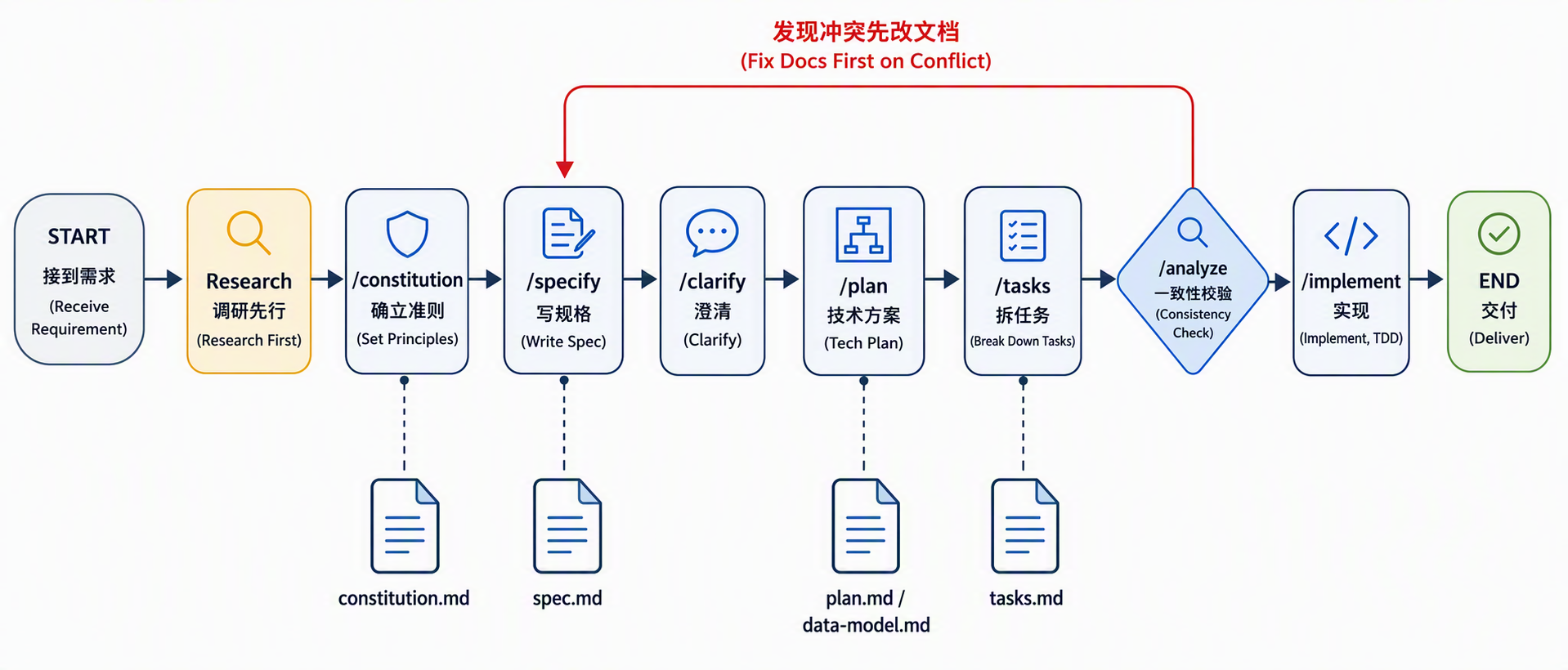
AI 友好基建的目标,是让 AI 能「看懂系统、介入全流程、稳定产出、持续进化」,遂记录关于现AI时代中关于前端基建质量标准的大讨论
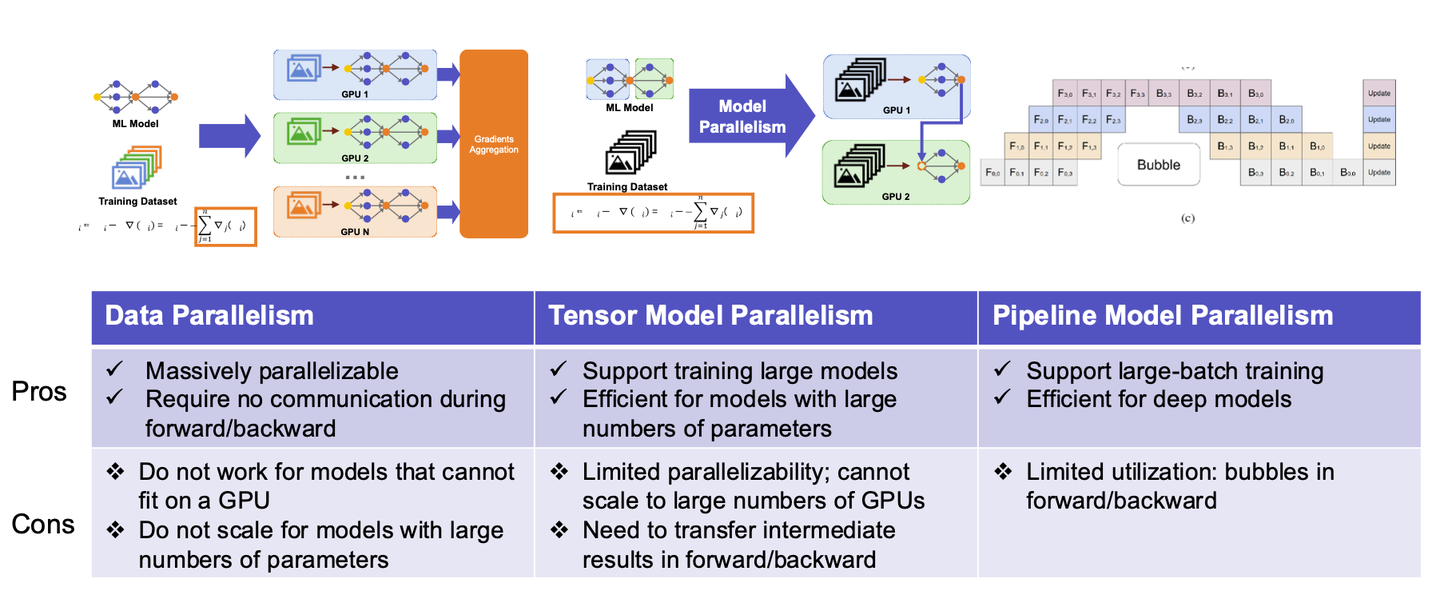
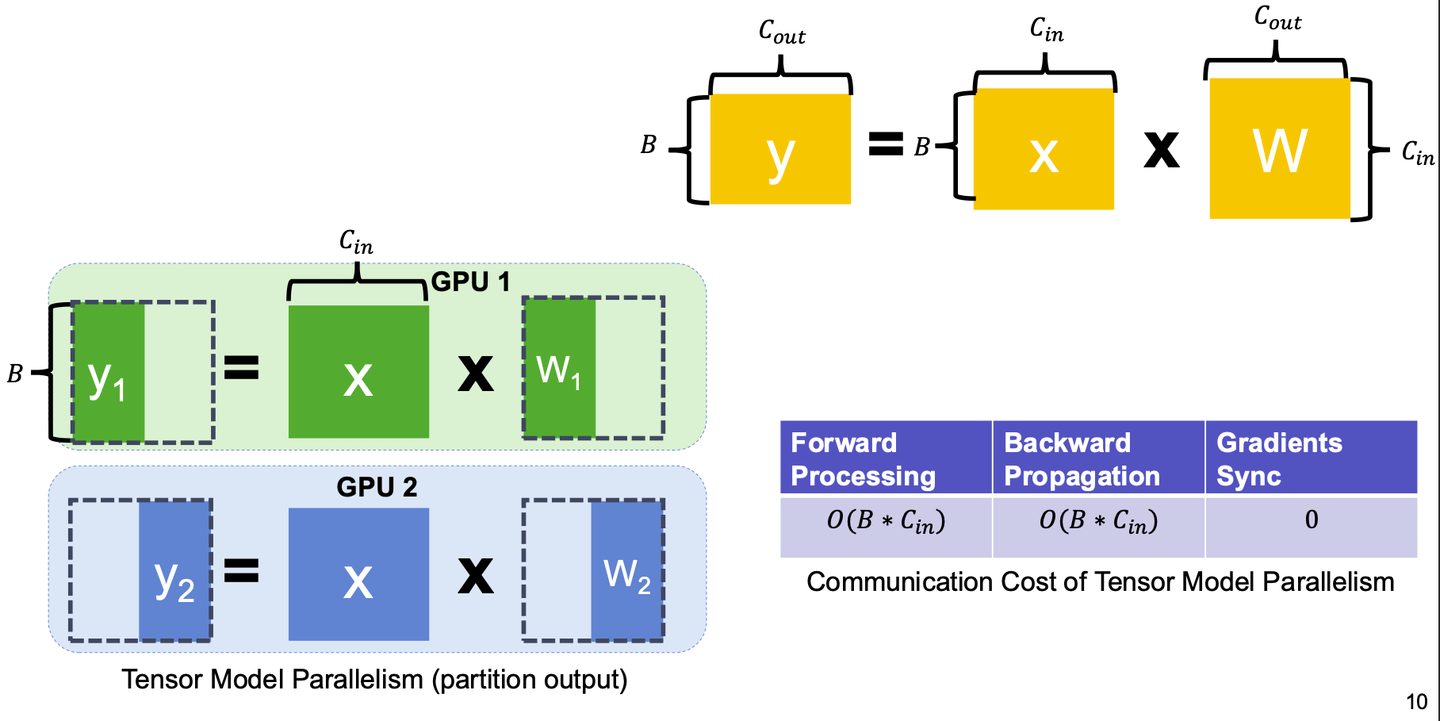
新的博客站!旧站点传送门 👇
音乐
暂无播放
0:00 0:00
148
14
210
467,355
0 天
0 天前
42296 次
29212 人