
教务处课表爬虫
大二上在学python,所以想要用python实现一下课表爬取。
(虽然python开课爬虫不怎么讲的都
本文仅供学习使用。
广州大学课程信息查询脚本
1. 概述
本脚本用于自动化登录广州大学教务系统,获取当前学期课程信息,主要功能包括:
- 通过浏览器自动化(Selenium)模拟用户登录,绕过滑块验证。
- 使用获取的Cookie通过
requests库发送API请求,获取课程数据。 - 结构化处理课程信息,并导出为JSON和CSV格式文件。
2. 环境依赖
2.1 运行环境
-
Python 3.7+
-
依赖库
1
pip install selenium requests pandas
2.2 配置
- 手动输入学号密码(脚本运行时会提示),查询时段的配置请求参数
- 后期待完善(
3. 功能模块
3.1 登录模块
功能描述
- 通过Selenium启动浏览器,访问教务系统登录页面。
- 自动填充学号、密码,并绕过滑块验证。
- 判断登录状态,成功后保存Cookie供后续请求使用。
输入参数
- 学号(
login_username) - 密码(
login_password)
关键逻辑
- 浏览器配置:禁用自动化检测标志(
excludeSwitches: ['enable-automation']),防止被识别为爬虫。 - 滑块验证绕过:通过执行JavaScript代码
navigator.webdriver = false。 - 登录状态检查:通过页面元素或关键词(如
登录成功)判断是否登录成功。
3.2 课程数据获取模块
功能描述
-
使用
requests库发送POST请求,携带登录后的Cookie和参数,获取课程数据。 -
数据接口:
http://jwxt.gzhu.edu.cn/jwglxt/kbcx/xskbcx_cxXsgrkb.html(F12大法
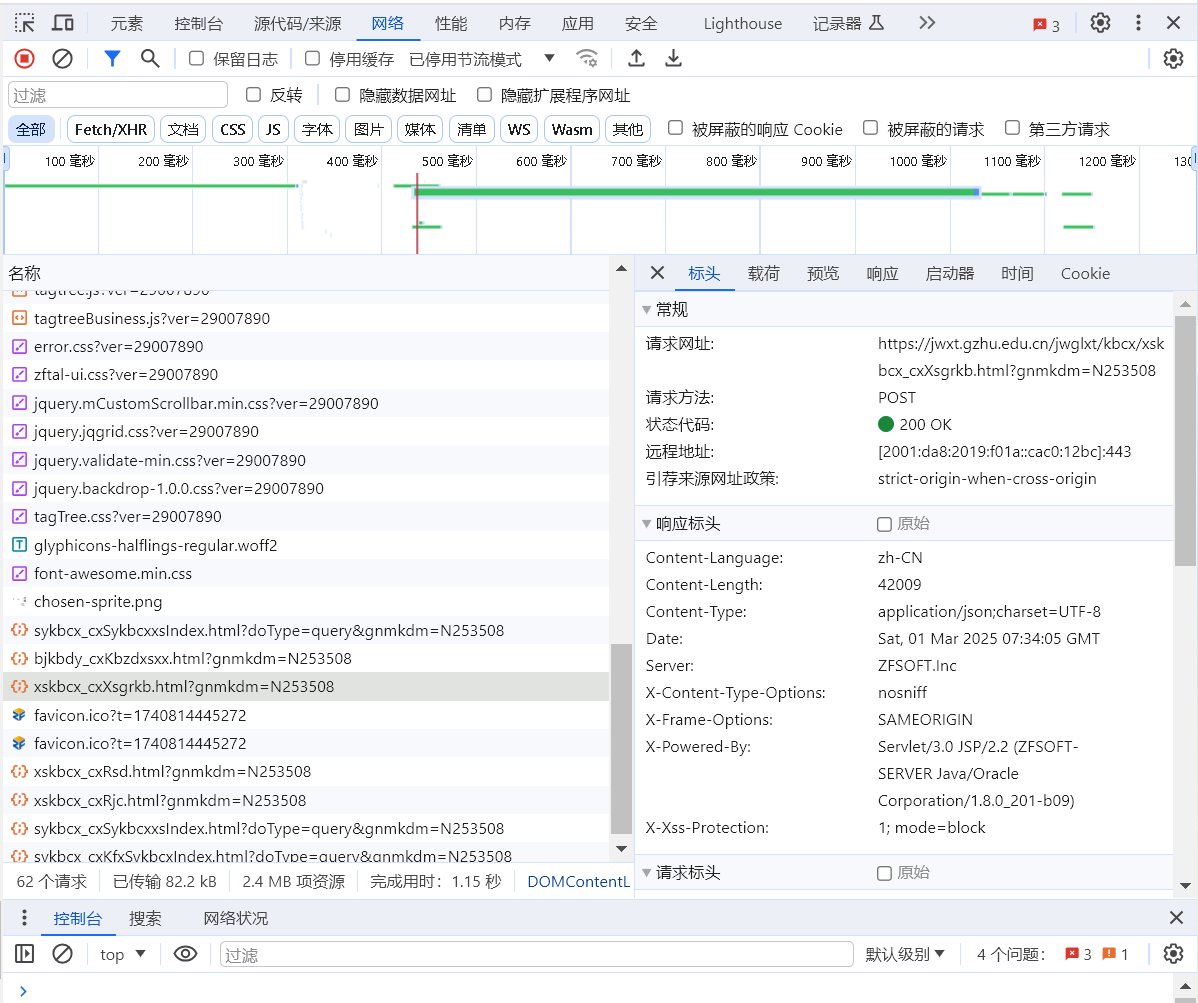
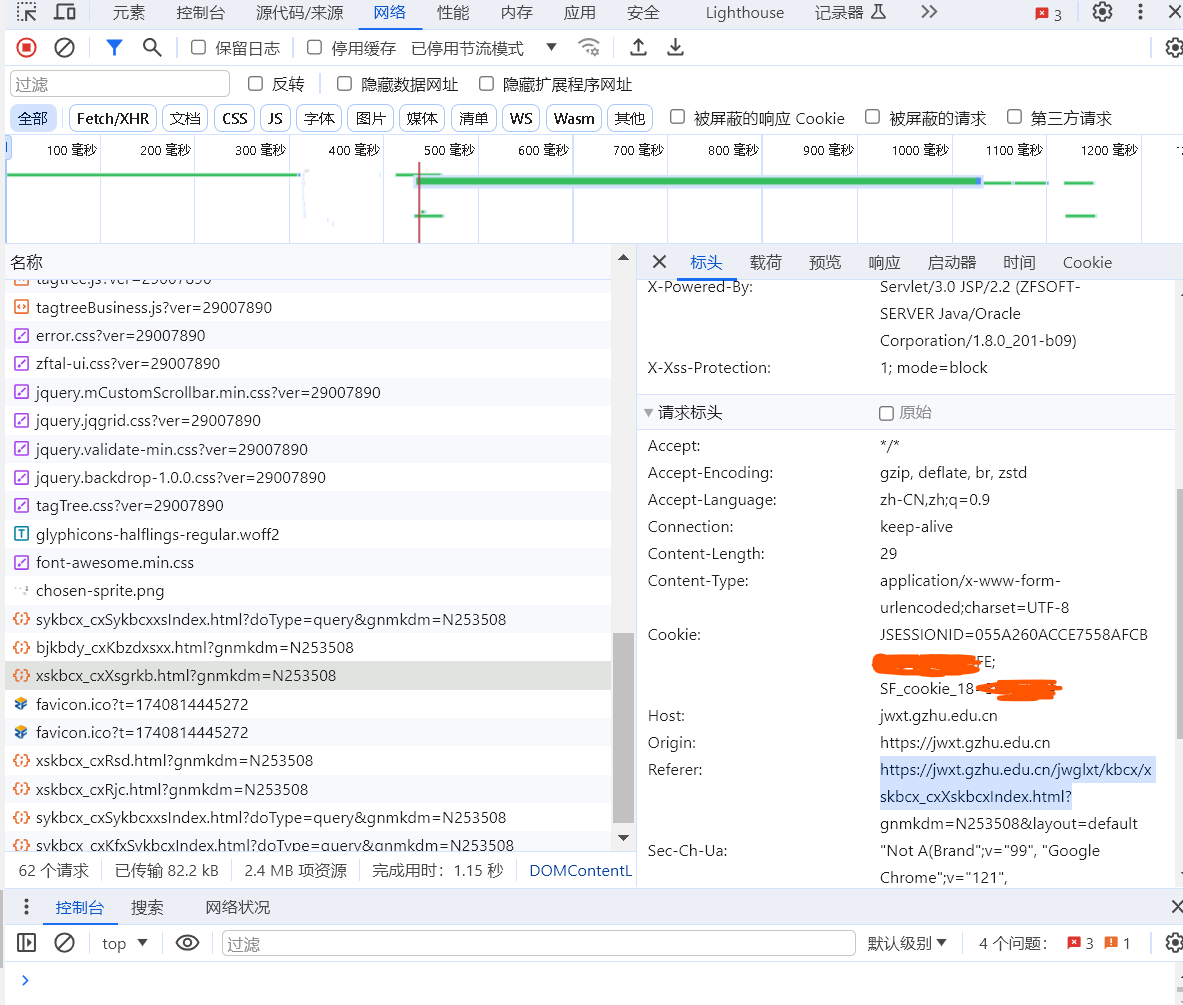
请求参数
1 | data = { |
请求头(Headers)
1 | headers = { |
3.3 数据处理与导出模块
功能描述
-
JSON数据处理
- 从原始响应中提取关键字段(如课程名称
kcmc、教室cdmc、节次jc)。 - 映射星期代码(
xqjmcMap)为中文(如1 → 周一)。 - 保存结构化的JSON文件(
extracted_courses.json)。
- 从原始响应中提取关键字段(如课程名称
-
CSV导出
-
使用
pandas将JSON数据转换为表格形式。 -
添加中文表头(如“课程名称”、“教室”)。
-
导出为CSV文件(
courses.csv),兼容Excel打开。
-
字段映射表
| 原始字段 | 中文表头 | 说明 |
|---|---|---|
kcmc |
课程名称 | 课程全称 |
cdmc |
教室 | 上课地点 |
jc |
节数 | 课程节次(如1-2节) |
xqjmc |
日期 | 星期几(周一至日) |
kcxszc |
课时安排 | 周次范围(如1-16周) |
4. 代码详解
4.1 登录流程
1 | # 防止打开浏览器后闪退 |
1 | # 等待响应 |
4.2 数据请求
1 |
|
4.3 JSON数据处理
1 | # 提取字段并重构数据 |
4.4 CSV导出逻辑
1 | # 使用pandas转换并导出 |
-
滑块验证更新:若教务系统更新滑块验证逻辑,需调整JavaScript绕过代码。
-
接口稳定性:课程查询接口(
xskbcx_cxXsgrkb.html)若变更URL,需同步更新。
6. 输出示例
6.1 JSON文件(extracted_courses.json)
和谐了部分隐私信息(
1 | { |
6.2 CSV文件(courses.csv)
| 课程名称 | 教室 | 节数 | 日期 | 课时安排 |
|---|---|---|---|---|
| 常微分方程1 | ███████ | 3-4 | 周一 | 1-16周 |
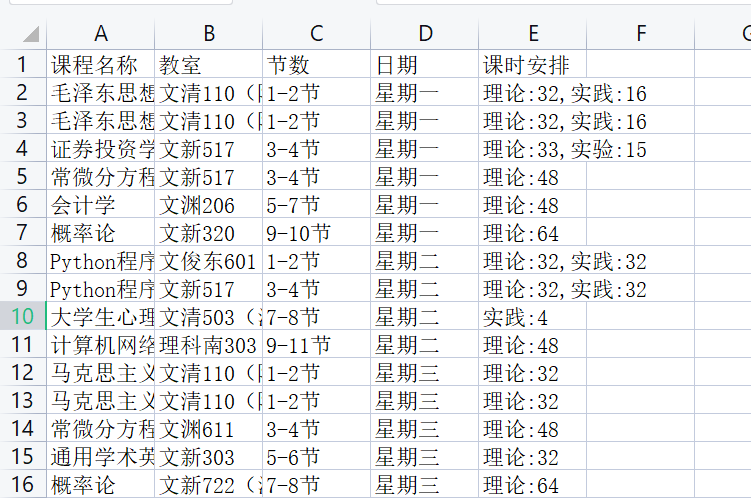
7. todo
- 可视化界面:集成
tkinter或Web框架(如Flask)提供GUI操作。 - 全校课表爬虫
评论