数据结构-绪论
Last Update:
Page View: loading...
1.1 数据结构的基本概念
数据、数据元素、数据对象、数据结构、存储结构、数据类型和抽象数据类型。
数据(data)是对客观事物的符号表示。在计算机科学中是指所有能输入到计算机中并被计算机程序处理的符号的总称。
数据元素(data element)是数据的基本单位,在计算机程序中通常作为一个整体进行考虑和处理。
数据对象(data object)是性质相同的数据元素的集合,是数据的一个子集。
数据结构(data structure)是相互之间存在一种或多种特定关系的数据元素的集合。
存储结构(物理结构)是数据结构在计算机中的表示(又称映像)。
数据类型(data type)是一个值的集合和定义在这个值集上的一组操作的总称。
抽象数据类型(Abstract Data Type)是指一个数学模型以及定义在该模型上的一组操作。
抽象数据类型的定义
1 | |
例子如下
抽象数据类型复数和有理数的定义(有理数是其分子、分母均为自然数且分母不为零的分数)。
1 | |
1 | |
根据数据元素之间关系的 不同特性,通常有下列几种类基本结构:
(1) 集合 结构中的 如生 数据元素之间除了“同属千一个集合”的关系外,别无其他关系
(2) 线性结构 结构中的数据元素之间存在一个对 一个的关系;
(3) 树形结构 结构中的数据元素之间存在一 个对多个的关系;
(4) 图状结构或网状结构 结构中的数据 元素之间存在多个对多个的关系。
1.1.2 数据结构三要素
① 逻辑结构
逻辑结构指数据元素之间存在的逻辑关系,是固有的客观联系;
逻辑结构分为线性结构与非线性结构,比如:线性表、树、图等;
② 存储结构
存储结构又称为物理结构,指数据结构在计算机中的表示(映像),是计算机内部的存储方法;
存储结构主要有顺序存储、链式存储、索引存储和散列存储;
一种逻辑结构通过映像便可以得到它的存储结构;
诸如顺序表、哈希表、链表这样的表述,它们既体现了逻辑结构(均为线性),又体现了存储结构(顺序、散列、链式);
而这样的表述我们往往就直接称之为数据结构;
诸如有序表,它只体现了逻辑结构(线性),而存储结构是未知的(可以是顺序、链式……);
不存在只体现存储结构而不体现逻辑结构的表述;
所以,我们认为:逻辑结构独立于存储结构。
③ 数据的运算(算法)
算法包括运算的定义(取决于逻辑结构,体现算法功能)与实现(取决于存储结构,体现于操作步骤)。
1.2 算法的基本概念
算法的 5 个重要特性:有穷性、确定性、有效性(可行性)、输入,输出;
一个好的算法的目标:正确性、可读性、鲁棒性、效率与低存储量需求。
1.3 算法分析
时间复杂度指算法所有语句被重复执行次数总和的数量级。
常见时间复杂度比较:
O(1) < O(log n) < O(n) < O(n log n) < O(n^2) < O(n^3) < O(2^n) < O(n!) < O(n^n)
(log 表示以 2 为底的对数)
空间复杂度指算法耗费存储空间的数量级。
1.4 时间复杂度的计算
计算时间复杂度
问题规模——> 输入量的多少
语句频度——> 一条语句的重复执行次数
执行时间<—— 所有语句频度之和
1.基本操作,即只有常数项,认为其时间复杂度为O(1)
2.顺序结构,时间复杂度按加法进行计算
3.循环结构,时间复杂度按乘法进行计算
4.分支结构,时间复杂度取最大值 判断一个算法的效率时,往往只需要关注操作数量的最高次项,其它次要项和常数项可以忽略
5.在没有特殊说明时,我们所分析的算法的时间复杂度都是指最坏时间复杂度
循环条件包含主体变量
将执行次数代入循环条件进行求解:
示例1:
1 | |
- 每次循环后 i =2t(t 为执行次数)
- 终止条件:2t ≤ n
- 解得 t ≤ log2n
- 时间复杂度:T(n) = O(logn)
示例2:
1 | |
- 令 t=i−3,则 i=t+3
- 代入条件:(t+3+1)2<n⟹(t+4)2<n
- 解得 t<n−4
- 时间复杂度:T(n)=O(n)
循环条件与主体变量无关
通过数学归纳法或递归展开直接计数:
示例(递归函数):
1 | |
- 递归方程:T(n)=1+T(n−1)
- 展开递推:T(n)=1+T(n−1)=1+1+T(n−2) ⋮=k+T(n−k)(当 k=n−1)=(n−1)+T(1)=O(n)
- 时间复杂度:T(n)=O(n)
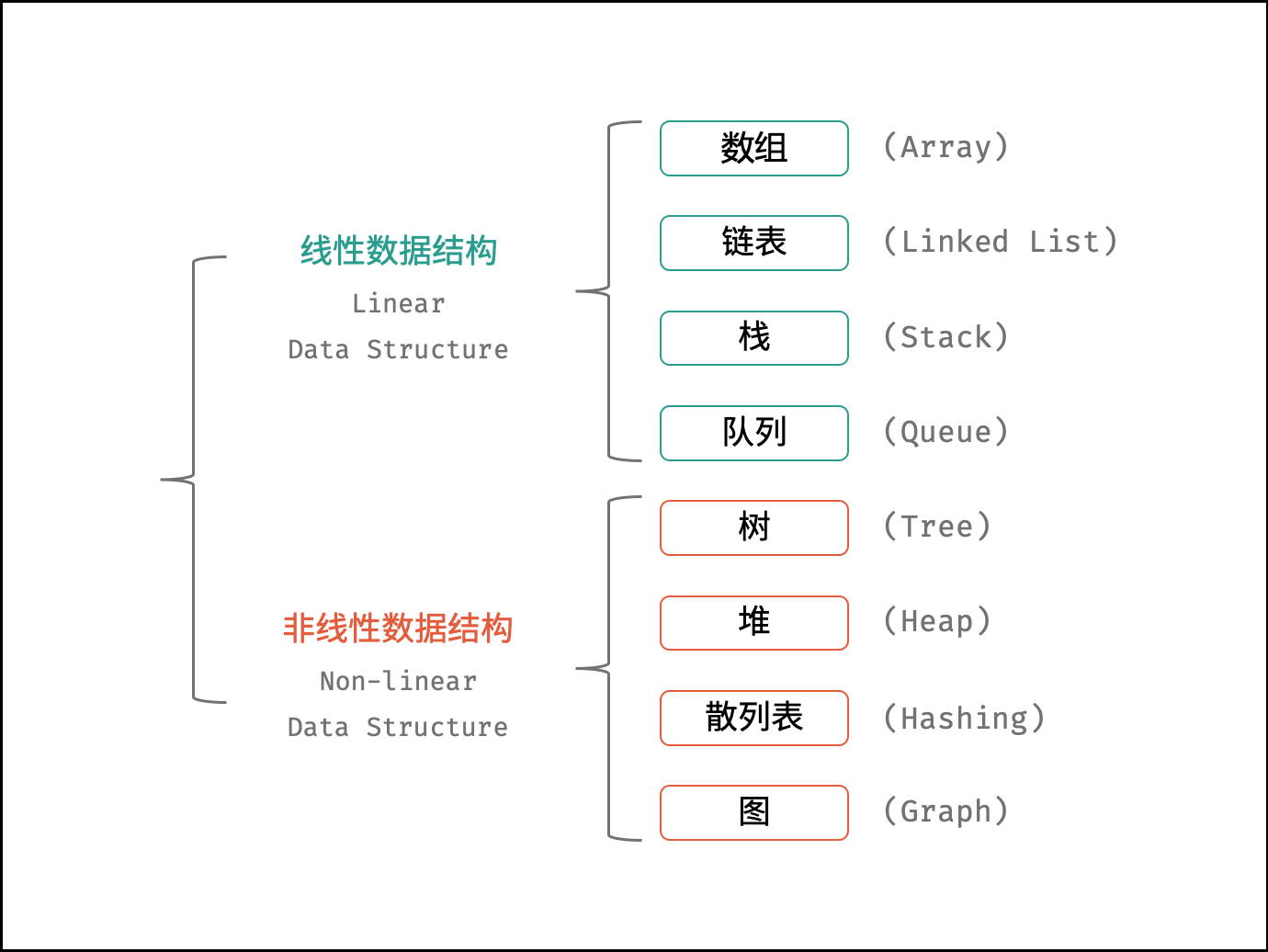
常见的数据结构
如下图所示,常见的数据结构可分为「线性数据结构」与「非线性数据结构」,具体为:「数组」、「链表」、「栈」、「队列」、「树」、「图」、「散列表」、「堆」。
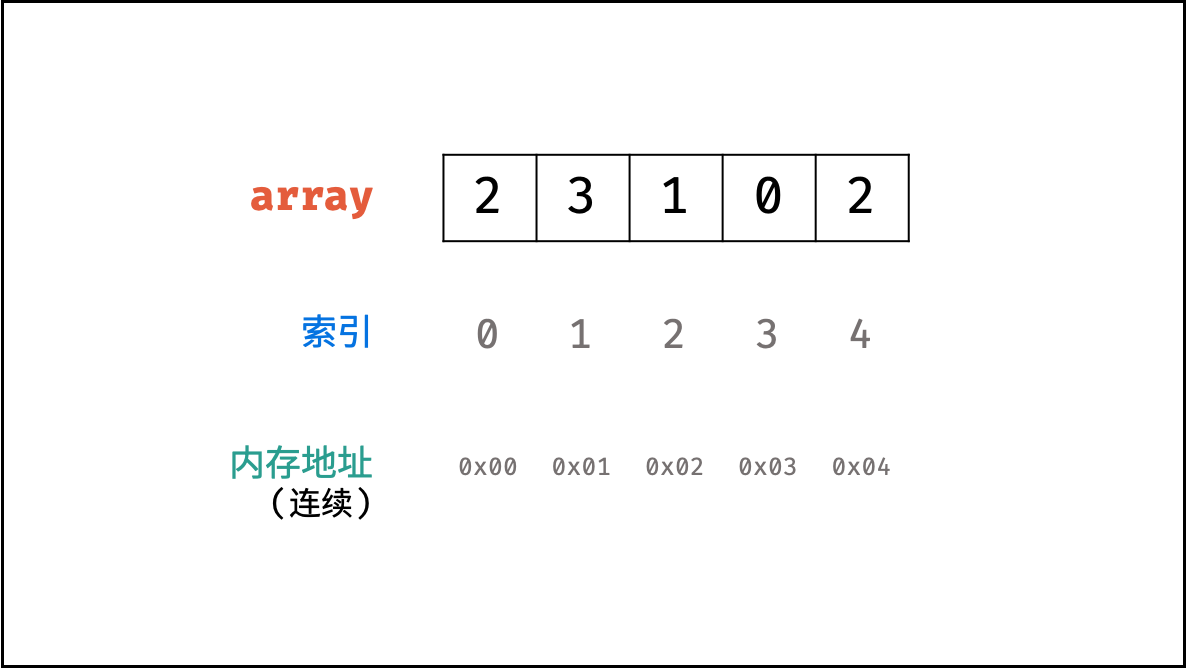
数组
数组是将相同类型的元素存储于连续内存空间的数据结构,其长度不可变。
如下图所示,构建此数组需要在初始化时给定长度,并对数组每个索引元素赋值,代码如下:
1 | |
或者可以使用直接赋值的初始化方式,代码如下:
1 | |
「可变数组」是经常使用的数据结构,其基于数组和扩容机制实现,相比普通数组更加灵活。常用操作有:访问元素、添加元素、删除元素。
1 | |
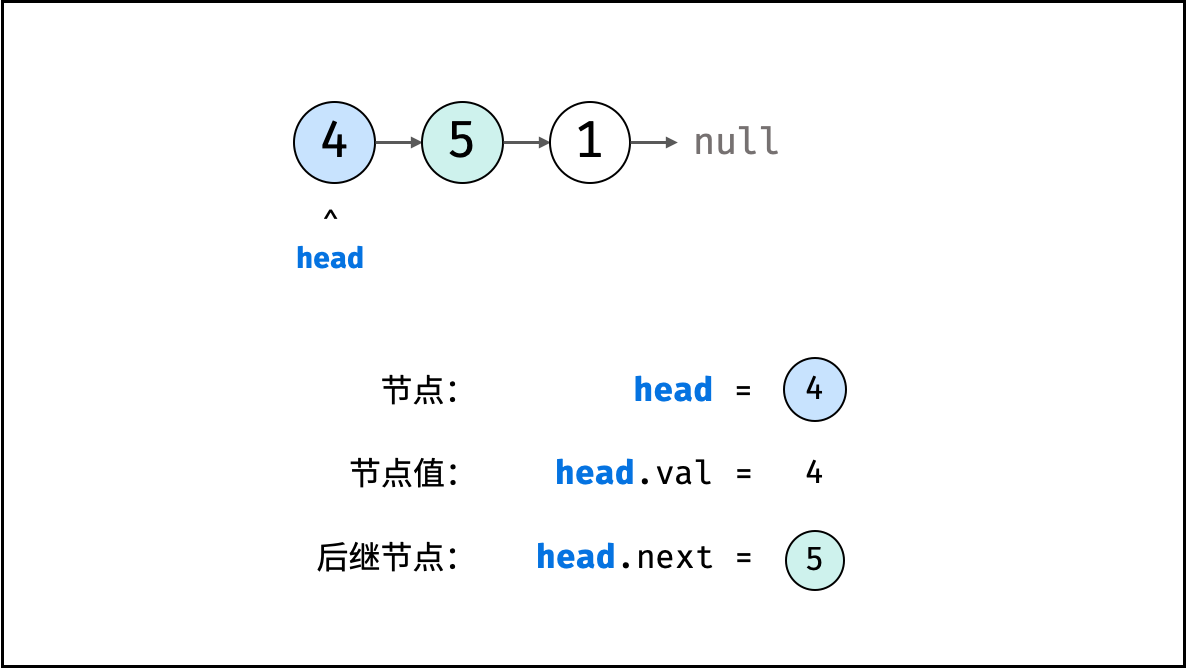
链表
链表以节点为单位,每个元素都是一个独立对象,在内存空间的存储是非连续的。链表的节点对象具有两个成员变量:「值 val」,「后继节点引用 next」 。
1 | |
如下图所示,建立此链表需要实例化每个节点,并构建各节点的引用指向。
1 | |
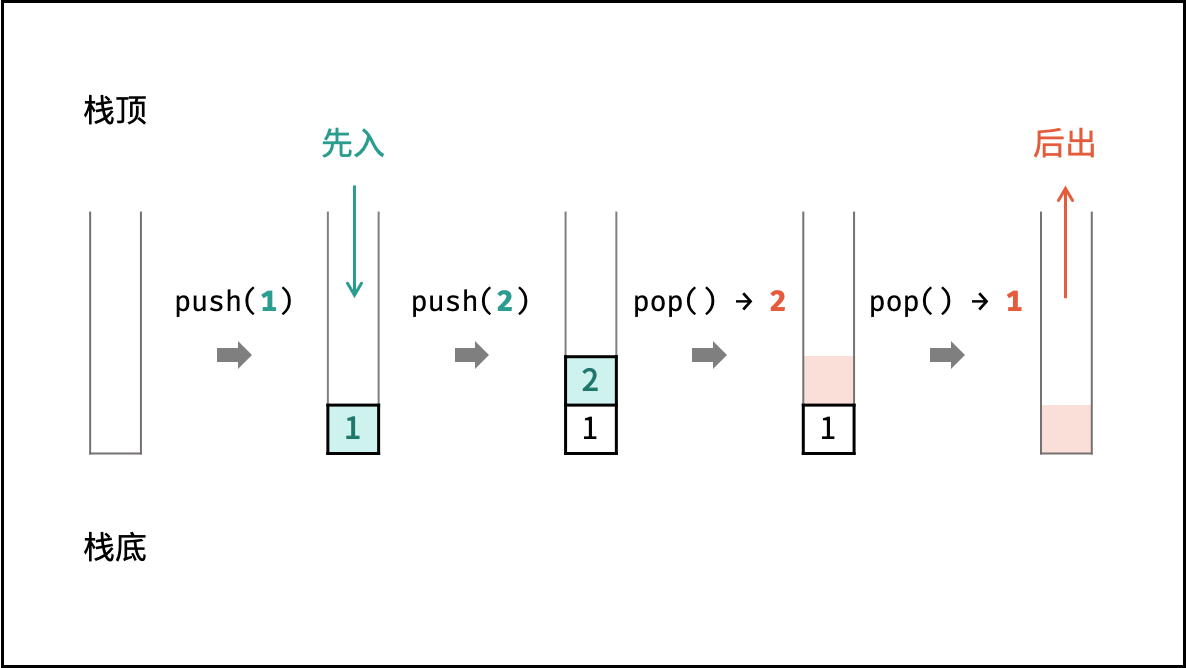
栈
栈是一种具有 「先入后出」 特点的抽象数据结构,可使用数组或链表实现。
1 | |
如下图所示,通过常用操作「入栈 push()」,「出栈 pop()」,展示了栈的先入后出特性。
1 | |
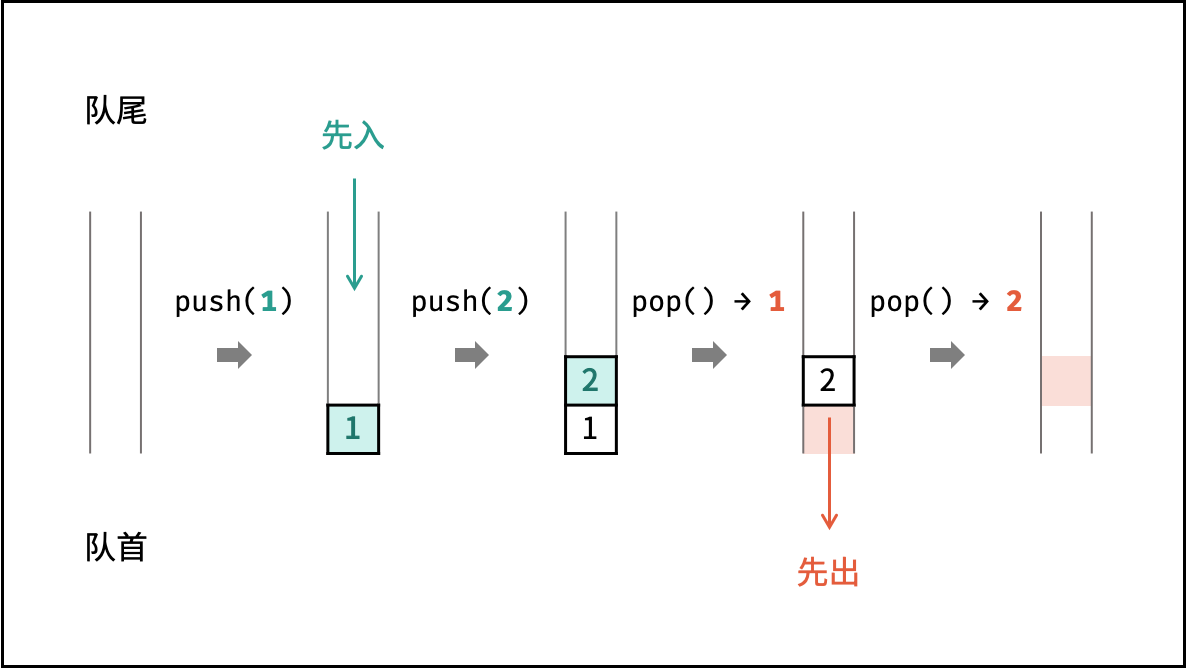
队列
队列是一种具有 「先入先出」 特点的抽象数据结构,可使用链表实现。
1 | |
如下图所示,通过常用操作「入队 push()」,「出队 pop()」,展示了队列的先入先出特性。
1 | |
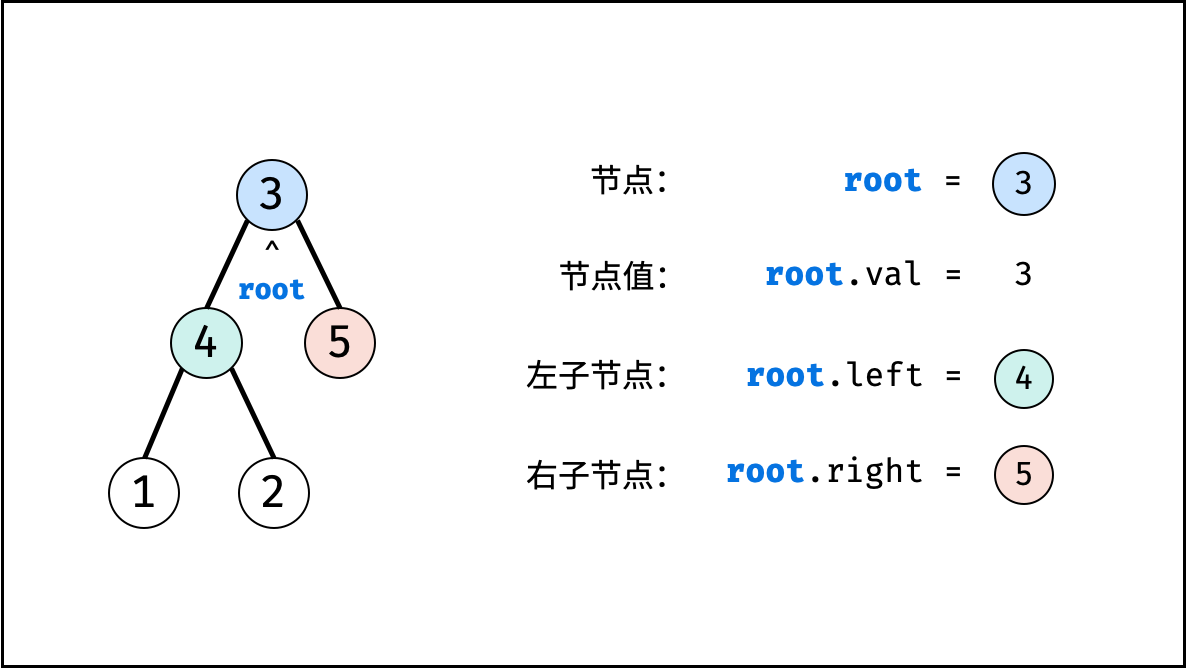
树
树是一种非线性数据结构,根据子节点数量可分为 「二叉树」 和 「多叉树」,最顶层的节点称为「根节点 root」。以二叉树为例,每个节点包含三个成员变量:「值 val」、「左子节点 left」、「右子节点 right」 。
1 | |
如下图所示,建立此二叉树需要实例化每个节点,并构建各节点的引用指向。
1 | |
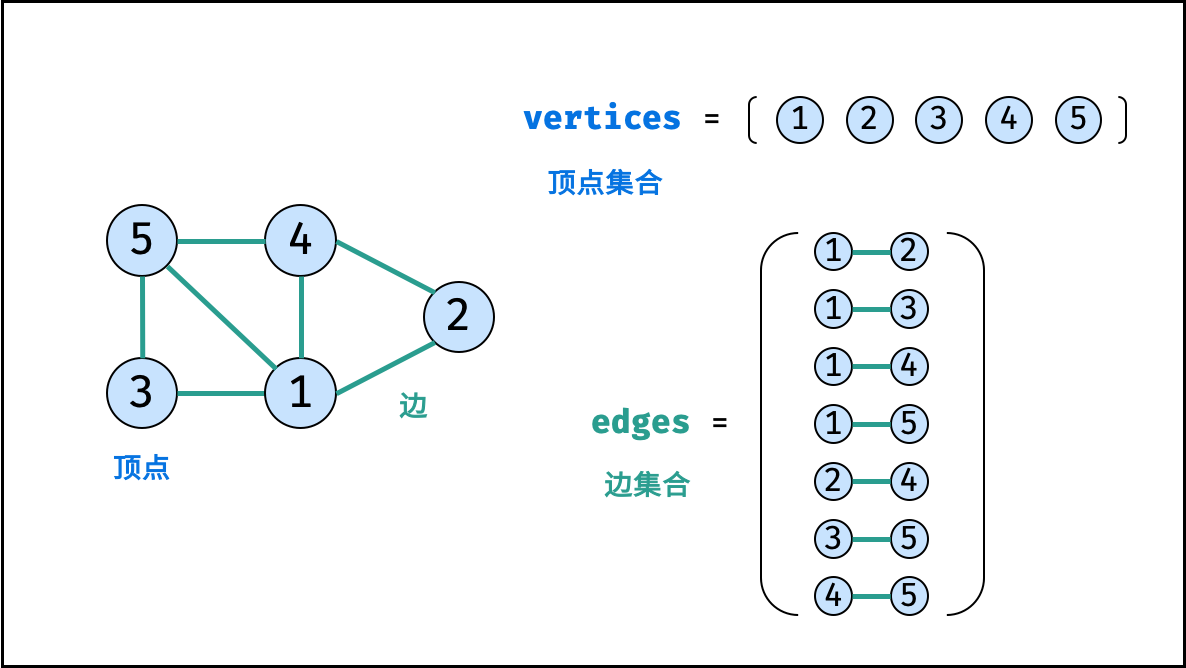
图
图是一种非线性数据结构,由「节点(顶点)vertex」和「边 edge」组成,每条边连接一对顶点。根据边的方向有无,图可分为「有向图」和「无向图」。本文 以无向图为例 开展介绍。
如下图所示,此无向图的 顶点 和 边 集合分别为:
- 顶点集合:
vertices = {1, 2, 3, 4, 5} - 边集合:
edges = {(1, 2), (1, 3), (1, 4), (1, 5), (2, 4), (3, 5), (4, 5)}
表示图的方法通常有两种:
邻接矩阵:
1 | |
邻接表:
- 顶点存储: 数组
vertices存储顶点值 - 边存储: 二维容器
edges存储边关系- 第一维
i表示顶点索引(对应vertices[i]) - 第二维
edges[i]存储该顶点连接的目标顶点值集合 edges[i]中的数字直接表示目标顶点值**(非索引)- 例如
edges[0] = [1,2,3,4]表示顶点1连接到值2/3/4/5(注意实际值比索引大1)
- 第一维
1 | |
邻接矩阵 VS 邻接表 :
邻接矩阵的大小只与节点数量有关,即 N2N2 ,其中 NN 为节点数量。因此,当边数量明显少于节点数量时,使用邻接矩阵存储图会造成较大的内存浪费。
因此,邻接表 适合存储稀疏图(顶点较多、边较少); 邻接矩阵 适合存储稠密图(顶点较少、边较多)。
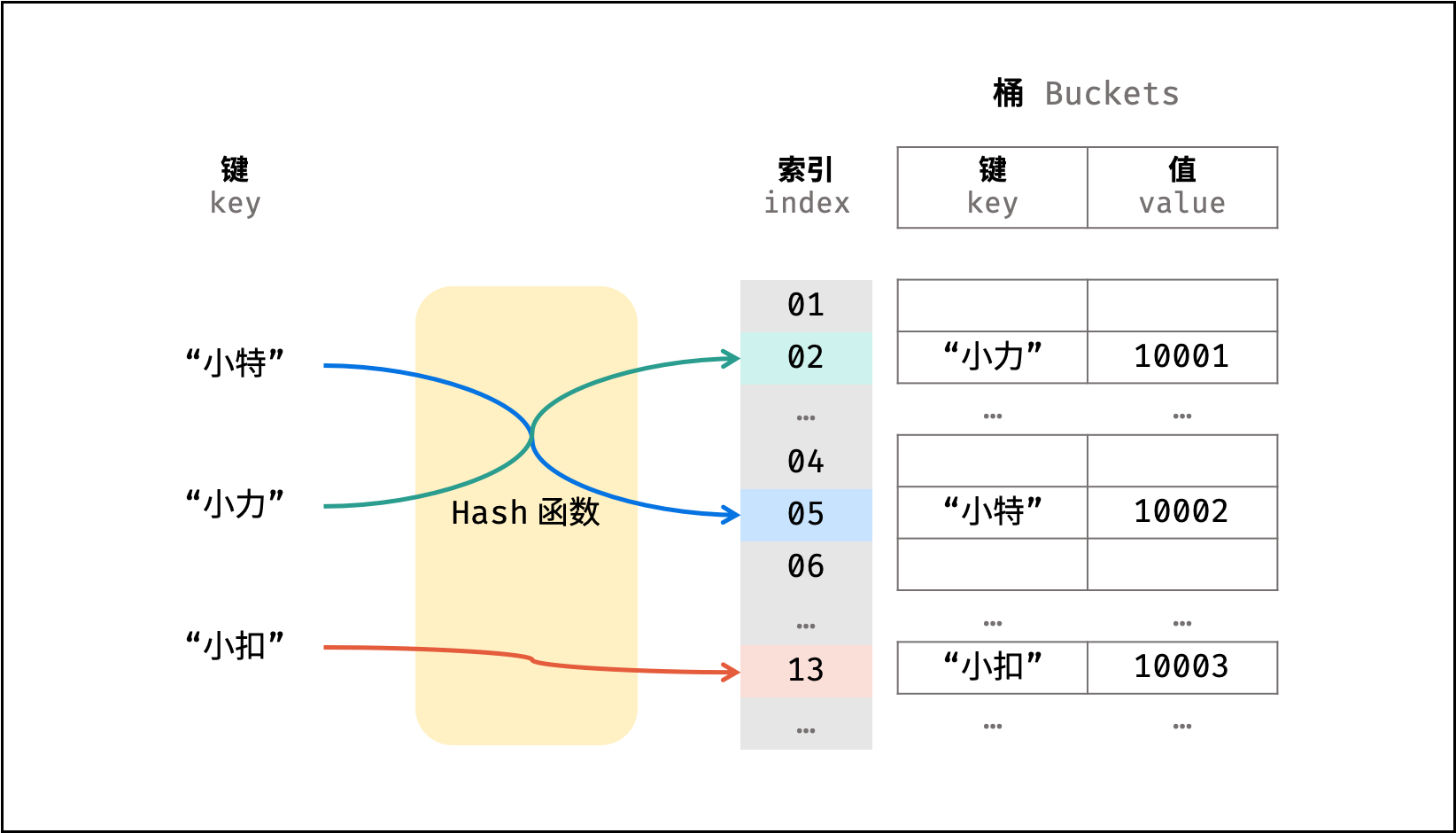
散列表
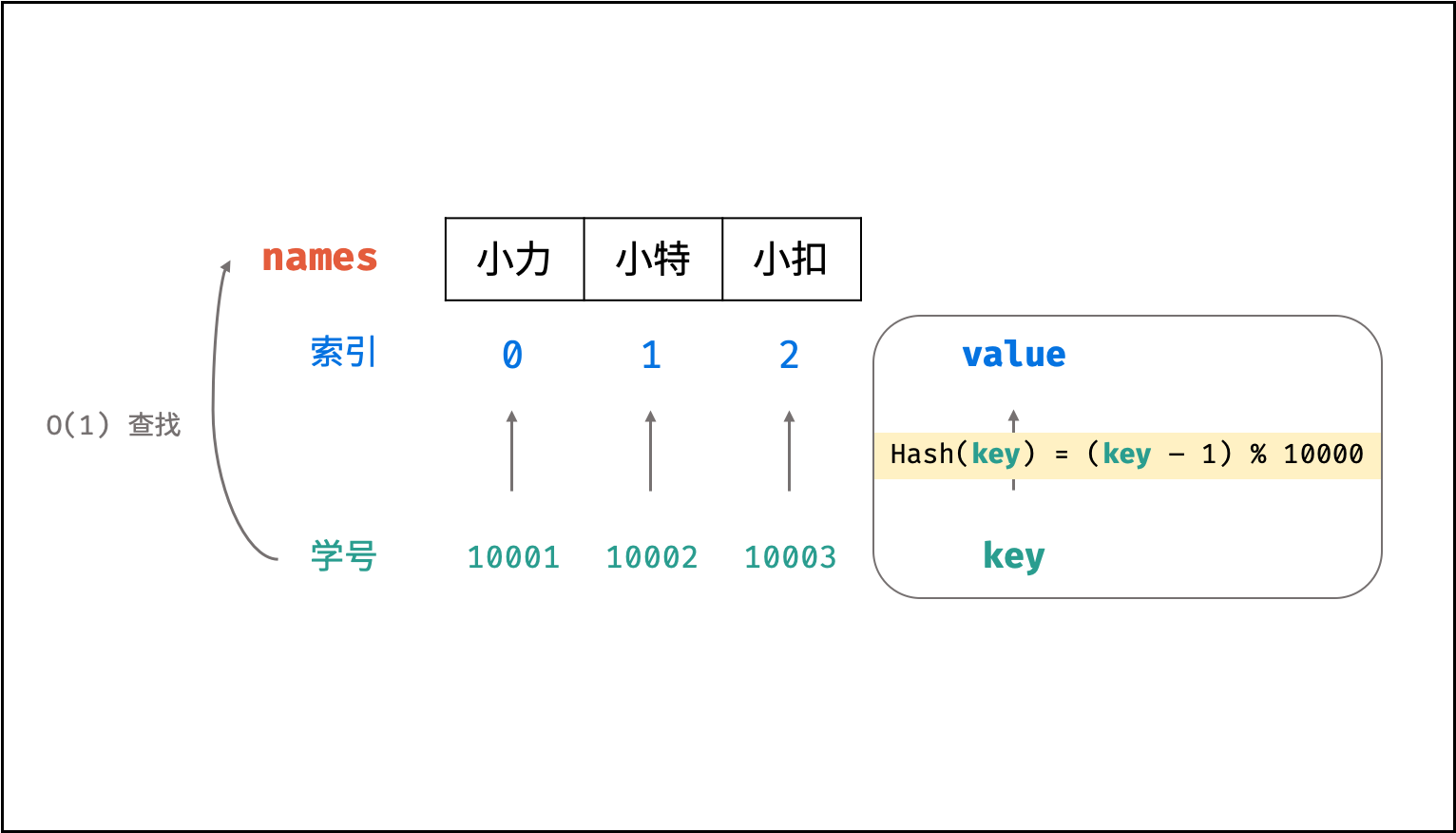
散列表是一种非线性数据结构,通过利用 Hash 函数将指定的「键 key」映射至对应的「值 value」,以实现高效的元素查找。
设想一个简单场景:小力、小特、小扣的学号分别为 10001, 10002, 10003 。
现需求从「姓名」查找「学号」。
则可通过建立姓名为 key ,学号为 value 的散列表实现此需求,代码如下:
1 | |
Hash 函数设计示例 :
假设需求:从「学号」查找「姓名」。
将三人的姓名存储至以下数组中,则各姓名在数组中的索引分别为 0, 1, 2 。
1 | |
此时,我们构造一个简单的 Hash 函数( %% 为取余符号 ),公式和封装函数如下所示:
hash(key)=(key−1)%10000
1 | |
则我们构建了以学号为 key 、姓名对应的数组索引为 value 的散列表。利用此 Hash 函数,则可在 O(1)O(1) 时间复杂度下通过学号查找到对应姓名,即:
1 | |
以上设计只适用于此示例,实际的 Hash 函数需保证低碰撞率、 高鲁棒性等,以适用于各类数据和场景。
堆
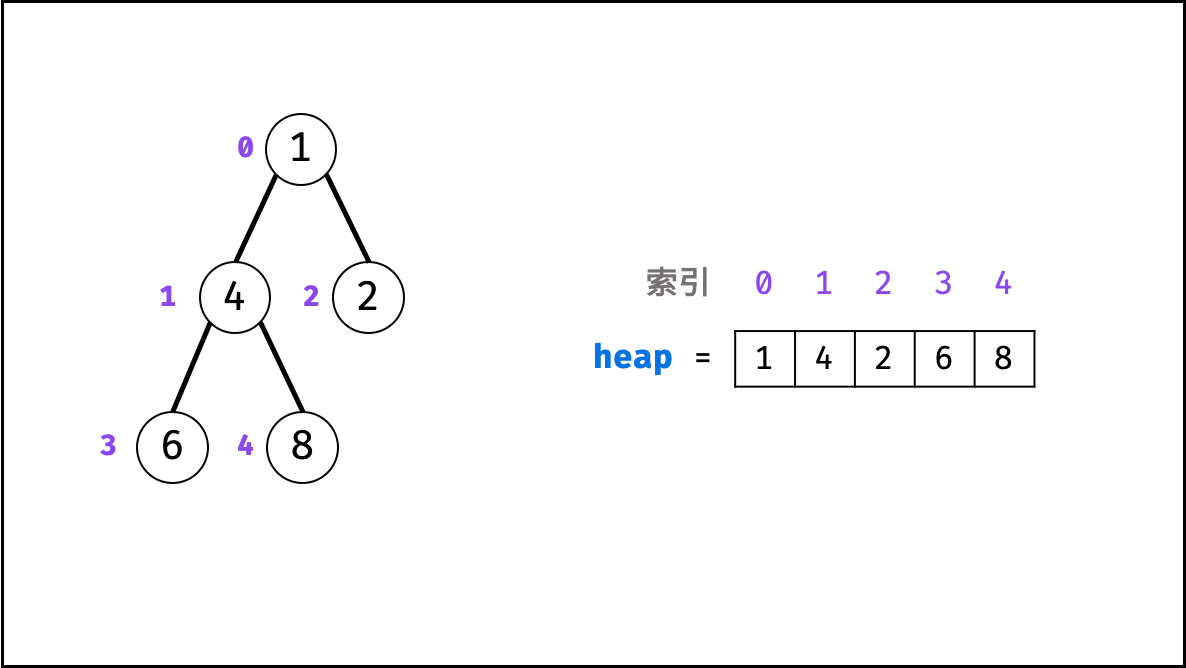
堆是一种基于「完全二叉树」的数据结构,可使用数组实现。以堆为原理的排序算法称为「堆排序」,基于堆实现的数据结构为「优先队列」。堆分为「大顶堆」和「小顶堆」,大(小)顶堆:任意节点的值不大于(小于)其父节点的值。
完全二叉树定义: 设二叉树深度为 kk ,若二叉树除第 kk 层外的其它各层(第 11 至 k−1k−1 层)的节点达到最大个数,且处于第 kk 层的节点都连续集中在最左边,则称此二叉树为完全二叉树。
如下图所示,为包含 1, 4, 2, 6, 8 元素的小顶堆。将堆(完全二叉树)中的结点按层编号,即可映射到右边的数组存储形式。
通过使用「优先队列」的「压入 push()」和「弹出 pop()」操作,即可完成堆排序,实现代码如下:
1 | |