链表(链式存储结构) 链表又称单链表、链式存储结构,用于存储逻辑关系为“一对一”的数据。
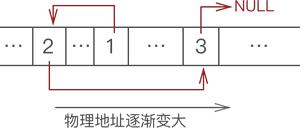
和顺序表不同,使用链表存储数据,不强制要求数据在内存中集中存储,各个元素可以分散存储在内存中。例如,使用链表存储 {1,2,3},各个元素在内存中的存储状态可能是:
可以看到,数据不仅没有集中存放,在内存中的存储次序也是混乱的。那么,链表是如何存储数据间逻辑关系的呢?
链表存储数据间逻辑关系的实现方案是:为每一个元素配置一个指针,每个元素的指针都指向自己的直接后继元素,如下图所示:
显然,我们只需要记住元素 1 的存储位置,通过它的指针就可以找到元素 2,通过元素 2 的指针就可以找到元素 3,以此类推,各个元素的先后次序一目了然。
像图 2 这样,数据元素随机存储在内存中,通过指针维系数据之间“一对一”的逻辑关系,这样的存储结构就是链表。
结点(节点)
很多教材中,也将“结点”写成“节点”,它们是一个意思。
在链表中,每个数据元素都配有一个指针,这意味着,链表上的每个“元素”都长下图这个样子:
数据域用来存储元素的值,指针域用来存放指针。数据结构中,通常将图 3 这样的整体称为结点。
也就是说,链表中实际存放的是一个一个的结点,数据元素存放在各个结点的数据域中。举个简单的例子,图 2 中 {1,2,3} 的存储状态用链表表示,如下图所示:
在 C 语言中,可以用结构体表示链表中的结点,例如:
1 2 3 4 typedef struct link {char elem; struct link * next;
我们习惯将结点中的指针命名为 next,因此指针域又常称为“Next 域”。
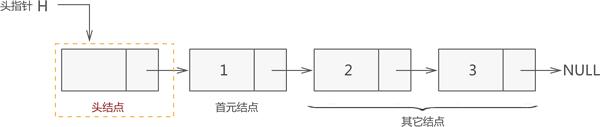
头结点、头指针和首元结点 图 4 所示的链表并不完整,一个完整的链表应该由以下几部分构成:
头指针:一个和结点类型相同的指针,它的特点是:永远指向链表中的第一个结点。上文提到过,我们需要记录链表中第一个元素的存储位置,就是用头指针实现。
结点:链表中的节点又细分为头结点、首元结点和其它结点:
头结点:某些场景中,为了方便解决问题,会故意在链表的开头放置一个空结点,这样的结点就称为头结点。也就是说,头结点是位于链表开头、数据域为空(不利用)的结点。
首元结点:指的是链表开头第一个存有数据的结点。
其他节点:链表中其他的节点。
也就是说,一个完整的链表是由头指针和诸多个结点构成的。每个链表都必须有头指针,但头结点不是必须的。
例如,创建一个包含头结点的链表存储 {1,2,3},如下图所示:
再次强调,头指针永远指向链表中的第一个结点。换句话说,如果链表中包含头结点,那么头指针指向的是头结点,反之头指针指向首元结点。
链表的创建 创建一个链表,实现步骤如下:
定义一个头指针;
创建一个头结点或者首元结点,让头指针指向它;
每创建一个结点,都令其直接前驱结点的指针指向它。
例如,创建一个存储 {1,2,3,4} 且无头节点的链表,C 语言实现代码为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 Link* initLink () {int i;NULL ;malloc (sizeof (Link));1 ;NULL ;for (i = 2 ; i < 5 ; i++) {malloc (sizeof (Link));NULL ;return p;
再比如,创建一个存储 {1,2,3,4} 且含头节点的链表,则 C 语言实现代码为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 Link* initLink () {int i;NULL ;malloc (sizeof (Link));0 ;NULL ;for (i = 1 ; i < 5 ; i++) {malloc (sizeof (Link));NULL ;return p;
链表的使用 对于创建好的链表,我们可以依次获取链表中存储的数据,例如:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 #include <stdio.h> #include <stdlib.h> typedef struct link {int elem;struct link * next;Link* initLink () {int i;NULL ;malloc (sizeof (Link));0 ;NULL ;for (i = 1 ; i < 5 ; i++) {malloc (sizeof (Link));NULL ;return p;void display (Link* p) while (temp) {printf ("%d " , temp->elem);free (f);printf ("\n" );int main () NULL ;printf ("初始化链表为:\n" );initLink ();display (p);return 0 ;
程序中创建的是带头结点的链表,头结点的数据域存储的是元素 0,因此最终的输出结果为:
0 1 2 3 4
如果不想输出头结点的值,可以将 p->next 作为实参传递给 display() 函数。
如果程序中创建的是不带头结点的链表,最终的输出结果应该是:
1 2 3 4
单链表的基本操作 学会创建链表之后,本节继续讲解链表的一些基本操作,包括向链表中添加数据、删除链表中的数据、查找和更改链表中的数据。
首先,创建一个带头结点的链表,链表中存储着 {1,2,3,4}:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 typedef struct link {int elem;struct link * next;Link* initLink () {int i;NULL ;malloc (sizeof (Link));0 ;NULL ;for (i = 1 ; i < 5 ; i++) {malloc (sizeof (Link));NULL ;return p;
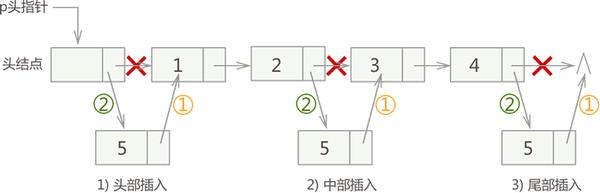
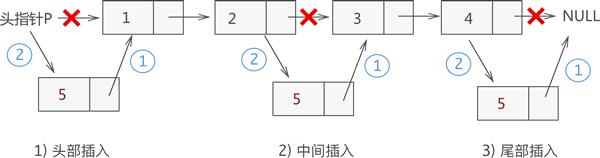
链表插入元素 同顺序表一样,向链表中增添元素,根据添加位置不同,可分为以下 3 种情况:
插入到链表的头部,作为首元节点;
插入到链表中间的某个位置;
插入到链表的最末端,作为链表中最后一个结点;
对于有头结点的链表,3 种插入元素的实现思想是相同的,具体步骤是:
将新结点的 next 指针指向插入位置后的结点;
将插入位置前结点的 next 指针指向插入结点;
例如,在链表 {1,2,3,4}的基础上分别实现在头部、中间、尾部插入新元素 5,其实现过程如下图所示:
从图中可以看出,虽然新元素的插入位置不同,但实现插入操作的方法是一致的,都是先执行步骤 1 ,再执行步骤 2。实现代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 void insertElem (Link* p, int elem, int add) int i;NULL ;for (i = 1 ; i < add; i++) {if (temp == NULL ) {printf ("插入位置无效\n" );return ;malloc (sizeof (Link));
注意:链表插入元素的操作必须是先步骤 1,再步骤 2;反之,若先执行步骤 2,除非再添加一个指针,作为插入位置后续链表的头指针,否则会导致插入位置后的这部分链表丢失,无法再实现步骤 1。
对于没有头结点的链表,在头部插入结点比较特殊,需要单独实现。
和 2)、3) 种情况相比,由于链表没有头结点,在头部插入新结点,此结点之前没有任何结点,实现的步骤如下:
将新结点的指针指向首元结点;
将头指针指向新结点。
实现代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 Link* insertElem (Link* p, int elem, int add) {if (add == 1 ) {malloc (sizeof (Link));return p;else {int i;NULL ;for (i = 1 ; i < add-1 ; i++) {if (temp == NULL ) {printf ("插入位置无效\n" );return p;malloc (sizeof (Link));return p;
注意当 add==1 成立时,形参指针 p 的值会发生变化,因此需要它的新值作为函数的返回值返回。
链表删除元素 从链表中删除指定数据元素时,实则就是将存有该数据元素的节点从链表中摘除。
对于有头结点的链表来说,无论删除头部(首元结点)、中部、尾部的结点,实现方式都一样,执行以下三步操作:
找到目标元素所在结点的直接前驱结点;
将目标结点从链表中摘下来;
手动释放结点占用的内存空间;
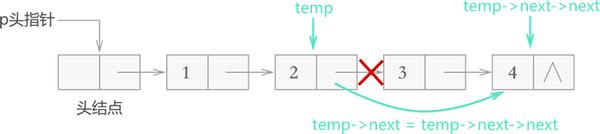
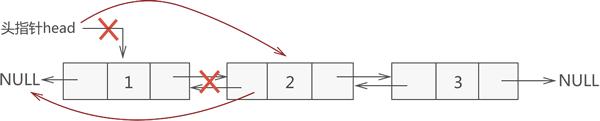
从链表上摘除目标节点,只需找到该节点的直接前驱节点 temp,执行如下操作:
1 temp->next=temp->next->next;
例如,从存有 {1,2,3,4}的链表中删除存储元素 3 的结点,则此代码的执行效果如图 3 所示:
实现代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 int delElem (Link* p, int elem) NULL , *temp = p;int find = 0 ;while (temp->next) {if (temp->next->elem == elem) {1 ;break ;if (find == 0 ) {return -1 ;else free (del);return 1 ;
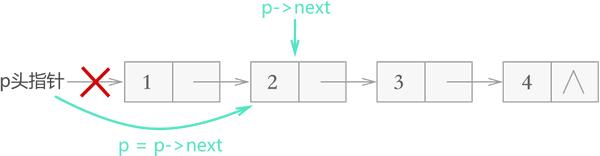
对于不带头结点的链表,需要单独考虑删除首元结点的情况,删除其它结点的方式和上图完全相同,如下图所示:
实现代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 int delElem (Link** p, int elem) NULL , *temp = *p;if (temp->elem == elem) {free (temp);return 1 ;else int find = 0 ;while (temp->next) {if (temp->next->elem == elem) {1 ;break ;if (find == 0 ) {return -1 ;else free (del);return 1 ;
函数返回 1 时,表示删除成功;返回 -1,表示删除失败。注意,该函数的形参 p 为二级指针,调用时需要传递链表头指针的地址。
链表查找元素 在链表中查找指定数据元素,最常用的方法是:从首元结点开始依次遍历所有节点,直至找到存储目标元素的结点。如果遍历至最后一个结点仍未找到,表明链表中没有存储该元素。
因此,链表中查找特定数据元素的 C 语言实现代码为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 int selectElem (Link* p, int elem) int i = 1 ;while (p) {if (p->elem == elem) {return i;return -1 ;
注意第 5 行代码,对于有结点的链表,需要先将 p 指针指向首元结点;反之,对于不带头结点的链表,注释掉第 5 行代码即可。
链表更新元素 更新链表中的元素,只需通过遍历找到存储此元素的节点,对节点中的数据域做更改操作即可。
直接给出链表中更新数据元素的 C 语言实现代码:
1 2 3 4 5 6 7 8 9 10 11 12 int amendElem (Link* p, int oldElem, int newElem) while (p) {if (p->elem == oldElem) {return 1 ;return -1 ;
函数返回 1,表示更改成功;返回数字 -1,表示更改失败。如果是没有头结点的链表,直接删除第 3 行代码即可。
双向链表 目前我们所学到的链表,无论是动态链表还是静态链表,表中各个节点都只包含一个指针(游标),且都统一指向直接后继节点,这类链表又统称为单向链表或单链表。
虽然单链表能 100% 存储逻辑关系为 “一对一” 的数据,但在解决某些实际问题时,单链表的执行效率并不高。例如,若实际问题中需要频繁地查找某个结点的前驱结点,使用单链表存储数据显然没有优势,因为单链表的强项是从前往后查找目标元素,不擅长从后往前查找元素。
解决此类问题,可以建立双向链表(简称双链表)。
双向链表是什么 从名字上理解双向链表,即链表是 “双向” 的,如下图所示:
“双向”指的是各节点之间的逻辑关系是双向的,头指针通常只设置一个。
从上图中可以看到,双向链表中各节点包含以下 3 部分信息(如图 2 所示):
指针域:用于指向当前节点的直接前驱节点;
数据域:用于存储数据元素。
指针域:用于指向当前节点的直接后继节点;
因此,双链表的节点结构用 C 语言实现为:
1 2 3 4 5 typedef struct line {struct line * prior; int data;struct line * next;
双向链表的创建 同单链表相比,双链表仅是各节点多了一个用于指向直接前驱的指针域。因此,我们可以在单链表的基础轻松实现对双链表的创建。
需要注意的是,与单链表不同,双链表创建过程中,每创建一个新节点都要与其前驱节点建立两次联系,分别是:
将新节点的 prior 指针指向直接前驱节点;
将直接前驱节点的 next 指针指向新节点;
这里给出创建双向链表的 C 语言实现代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 Line* initLine (Line* head) {NULL ;malloc (sizeof (Line));NULL ;NULL ;1 ;for (int i = 2 ; i <= 5 ; i++) {malloc (sizeof (Line));NULL ;NULL ;return head;
我们可以尝试着在 main 函数中输出创建的双链表,C 语言代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 #include <stdio.h> #include <stdlib.h> typedef struct line {struct line * prior; int data;struct line * next; Line* initLine (Line* head) {int i;NULL ;malloc (sizeof (Line));NULL ;NULL ;1 ;for (i = 2 ; i <= 5 ; i++) {malloc (sizeof (Line));NULL ;NULL ;return head;void display (Line* head) while (temp) {if (temp->next == NULL ) {printf ("%d\n" , temp->data);else {printf ("%d <-> " , temp->data);void free_line (Line* head) while (temp) {free (temp);int main () NULL ;initLine (head);display (head);printf ("链表中第 4 个节点的直接前驱是:%d" , head->next->next->next->prior->data);free_line (head);return 0 ;
程序运行结果:
1 <-> 2 <-> 3 <-> 4 <-> 5 链表中第 4 个节点的直接前驱是:3
双向链表基本操作 前面学习了如何创建一个双向链表,本节学习有关双向链表的一些基本操作,即如何在双向链表中添加、删除、查找或更改数据元素。
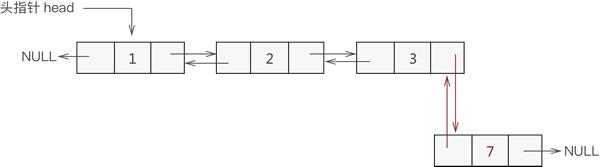
本节知识基于已熟练掌握双向链表创建过程的基础上,我们继续上节所创建的双向链表来学习本节内容,创建好的双向链表如下图所示:
图 双向链表示意图
双向链表添加节点 根据数据添加到双向链表中的位置不同,可细分为以下 3 种情况:
1) 添加至表头
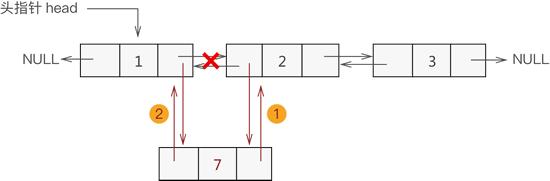
将新数据元素添加到表头,只需要将该元素与表头元素建立双层逻辑关系即可。
换句话说,假设新元素节点为 temp,表头节点为 head,则需要做以下 2 步操作即可:
temp->next=head; head->prior=temp;
将 head 移至 temp,重新指向新的表头;
例如,将新元素 7 添加至双链表的表头,则实现过程如图 2 所示:
图 添加元素至双向链表的表头
2) 添加至表的中间位置
同单链表添加数据类似,双向链表中间位置添加数据需要经过以下 2 个步骤,如下图所示:
新节点先与其直接后继节点建立双层逻辑关系;
新节点的直接前驱节点与之建立双层逻辑关系;
图 双向链表中间位置添加数据元素
3) 添加至表尾
与添加到表头是一个道理,实现过程如下(如图 4 所示):
找到双链表中最后一个节点;
让新节点与最后一个节点进行双层逻辑关系;
图 双向链表尾部添加数据元素
因此,我们可以试着编写双向链表添加数据的 C 语言代码,参考代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 Line* insertLine (Line* head, int data, int add) {malloc (sizeof (Line));NULL ;NULL ;if (add == 1 ) {else {int i;for (i = 1 ; i < add - 1 ; i++) {if (!body) {printf ("插入位置有误!\n" );return head;if (body && (body->next == NULL )) {else {return head;
双向链表删除节点 和添加结点的思想类似,在双向链表中删除目标结点也分为 3 种情况。
1) 删除表头结点
删除表头结点的过程如下图所示:
删除表头结点的实现过程是:
新建一个指针指向表头结点;
断开表头结点和其直接后续结点之间的关联,更改 head 头指针的指向,同时将其直接后续结点的 prior 指针指向 NULL;
释放表头结点占用的内存空间。
删除表中结点
删除表中结点的过程如下图所示:
删除表中结点的实现过程是:
找到目标结点,新建一个指针指向改结点;
将目标结点从链表上摘除;
释放该结点占用的内存空间。
删除表尾结点
删除表尾结点的过程如下图所示:
删除表尾结点的实现过程是:
找到表尾结点,新建一个指针指向该结点;
断点表尾结点和其直接前驱结点的关联,并将其直接前驱结点的 next 指针指向 NULL;
释放表尾结点占用的内存空间。
双向链表删除节点的 C 语言实现代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 Line* delLine (Line* head, int data) {while (temp) {if (temp->data == data) {if (temp->prior == NULL ) {if (head) {NULL ;NULL ;free (temp);return head;if (temp->prior && temp->next) {free (temp);return head;if (temp->next == NULL ) {NULL ;NULL ;free (temp);return head;printf ("表中没有目标元素,删除失败\n" );return head;
双向链表查找节点 通常情况下,双向链表和单链表一样都仅有一个头指针。因此,双链表查找指定元素的实现同单链表类似,也是从表头依次遍历表中元素。
C 语言实现代码为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 int selectElem (line * head,int elem) int i=1 ;while (t) {if (t->data==elem) {return i;return -1 ;
双向链表更改节点 更改双链表中指定结点数据域的操作是在查找的基础上完成的。实现过程是:通过遍历找到存储有该数据元素的结点,直接更改其数据域即可。
实现此操作的 C 语言实现代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 void amendElem (Line* p, int oldElem, int newElem) int find = 0 ;while (temp)if (temp->data == oldElem) {1 ;break ;if (find == 1 ) {return ;printf ("链表中未找到目标元素,更改失败\n" );
循环链表 无论静态链表还是动态链表,有时在解决具体问题时,需要我们对其结构进行稍微地调整。比如,可以把链表的两头连接,使其成为了一个环状链表,通常称为循环链表。
和它名字的表意一样,只需要将表中最后一个结点的指针指向头结点,链表就能成环儿,如下图所示。
需要注意的是,虽然循环链表成环状,但本质上还是链表,因此在循环链表中,依然能够找到头指针和首元节点等。循环链表和普通链表相比,唯一的不同就是循环链表首尾相连,其他都完全一样。
这里给大家一个循环链表的实例,用循环链表实现约瑟夫环
循环链表实现约瑟夫环 - 玩转C语言和数据结构xiexuewu.github.io/view/7.html
双向循环链表 我们知道,单链表通过首尾连接可以构成单向循环链表,如下图所示:
同样,双向链表也可以进行首尾连接,构成双向循环链表。如下图所示:
解决某些问题,可能既需要正向遍历数据,又需要逆向遍历数据,这时就可以考虑使用双向循环链表。
双向循环链表的创建 创建双向循环链表,只需在创建完成双向链表的基础上,将其首尾节点进行双向连接即可。
C 语言实现代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 Line* initLine (Line* head) {int i;NULL ;malloc (sizeof (Line));NULL ;NULL ;1 ;for (i = 2 ; i <= 3 ; i++) {malloc (sizeof (Line));NULL ;NULL ;return head;
通过向 main 函数中调用 initLine 函数,就可以成功创建一个存储有 {1,2,3} 数据的双向循环链表,其完整的 C 语言实现代码为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 #include <stdio.h> #include <stdlib.h> typedef struct line {struct line * prior; int data;struct line * next; Line* initLine (Line* head) {int i;NULL ;malloc (sizeof (Line));NULL ;NULL ;1 ;for (i = 2 ; i <= 3 ; i++) {malloc (sizeof (Line));NULL ;NULL ;return head;void display (Line* head) while (temp->next != head) {if (temp->next == NULL ) {printf ("%d\n" , temp->data);else {printf ("%d->" , temp->data);printf ("%d" , temp->data);void free_line (Line* head) NULL ;NULL ;while (temp) {free (temp);int main () NULL ;initLine (head);display (head);free_line (head);return 0 ;
程序输出结果如下:
1->2->3